当10亿个AI一起模拟未来:李飞飞和Karpathy共同押注的新赛道

本文来自微信公众号: 五源资本 5Y Capital ,作者:5Y Research,原文标题:《当10亿个AI一起模拟未来:李飞飞和Karpathy共同押注的新赛道|5Y Research》
今天这篇研究,我们试着梳理一个我自己非常感兴趣、但仍在学习理解中的AI前沿方向——Multi-Agents模拟预测。
记得2023年“斯坦福小镇”那篇论文刚出来的时候,我专门去跟一作Joon Sung Park的导师Michael S.Bernstein请教过,他当时分享了不少令人印象深刻的发现。但苦于token太贵,成本高到只能当学术实验来做。
跟他聊完之后,我实在太着迷了,就自己亲手搭了一个模拟环境。当时用的是Meta出的一个3D仿真平台Habitat,设计了一个客厅场景——沙发、电视,给里面的角色设定了《老友记》里的人物背景,看他们会做什么。
我当时特别想验证的是:能不能用AI来模拟人性的drama?就是人与人之间那些情绪起伏、猜疑、试探——”我拿出一把刀,虽然也没动,但你已经想跑了”的那种人情推理。结果还真出现了一些有意思的事情,两个虚拟角色自己聊着聊着,还会主动去开电视,后来其中一个居然问另一个:”你觉不觉得我们像是被模拟出来的?”另一个说:”怎么可能。”那个瞬间我觉得特别魔幻。
当然,今天我们再看这个方向,”世界模拟器”要模拟的东西远比drama大得多——群体决策、信息传播、情绪扩散、社会涌现。但回到2023年那个时间点,那次小实验让我切身感受到:这件事是可以做的,AI确实能捕捉到人性中那些非理性的、微妙的部分。
在今天世界模型的版图里,其实缺了一块重要拼图:我们对具身场景的世界模型,已经投入了大量研究;在生物领域也有虚拟细胞,本质上也是那个层面的世界模型。但针对人类社会组织形态,它的“世界模型”是什么?
世界模型做的事情,其实一直没变过:预测一个系统,在受到扰动后,会怎么变化。放在强化学习的语境下,就是”roll out”——在模型里把未来展开很多次,看哪条路径的结果更好,再把好的经验蒸馏回来,变成最优实践。这件事在物理和生物领域已经开始发生了,但在社会科学层面,我们才刚刚起步。
这就是为什么今天Multi-Agent模拟预测,非常值得关注,它不只是一个更快的调研工具,它可能是我们第一次真正有机会,为人类社会建一个可以反复运行的“世界模型”。
我们对这个方向的理解还不够深,写这篇更多是把目前看到的线索做一次整理,也希望能抛砖引玉。今年我们看了不少AI前沿领域,会逐步写成研究分享出来。如果你对这些方向有更深的思考,非常欢迎来交流碰撞,我们随时在线。
当2024年美国大选中,特朗普遭遇刺杀未遂后,一家AI创业公司Aaru的系统里,一大批“虚拟AI选民”迅速倒向了他。
但几个小时后,随着枪手的更多信息浮出水面,许多虚拟选民又改变了主意,重回民主党。在这个系统里,没有电话民调员,也没有传统焦点小组,只有几千个被设定为“像真实选民一样思考和受信息影响”的AI agents,在一个虚拟世界里,实时经历着与我们相同的新闻周期,在30秒到1分半钟内,跑完一轮推演。
Aaru的赌注是,未来最有价值的预测,不再是费时费力地调研一群真人怎么想,而是先造出一个会变化、会传播、会彼此影响的“数字社会”,演练成千上万次,再看最高概率的结果,将走向哪里。
2026年初,Aaru完成了以10亿美元估值的A轮融资,客户包括麦当劳、安永、拜耳、新锐电影公司A24,安永的人说:”这是战略级武器。”
如今硅谷,正在流行一句话:模拟(Simulation)就是人工智能的下一个前沿。
除了Aaru这样的年轻激进派,另一条更具学术分量的路线,也在迅速成形:2023年搞出”斯坦福小镇”、脱胎于斯坦福大学计算机科学系的Simile,也拿到了1亿美元A轮融资,个人投资者名单上赫然写着两个名字:李飞飞和Andrej Karpathy。
Andrej Karpathy在评价Simile时说:预训练大语言模型的本质形态,就是一个在互联网上高度多样化人群的文本上,训练出来的”模拟引擎”——为什么只模拟一个”人”,而不尝试模拟一个群体?

Simile的目标,就是先精仿出,可以代表真实个体、再进一步彼此互动的AI agents,最终把企业调研、财报电话会预演、大选民调,乃至更大尺度的社会推演,都变成计算机可反复运行的实验。
这也是为什么,把眼下这波趋势只叫”AI预测”,已经有些不够了。更准确的说法,或许是Multi-Agents(多智能体)模拟预测。
站在一个乐观派投资人的角度,我们觉得这个赛道卖的甚至不是”预测”,而是”批发价的后悔药”。在真实世界里犯一次错,代价可能很高昂;而在数字世界里犯一千次错,成本可能只是一顿饭钱。如果这个逻辑成立,它改变的不是某个行业的效率,而是整个人类社会”试错”的经济学。
01、
AI预测的“进步曲线”,很像2018年DeepMind破解蛋白质结构
过去2年间,AI在预测方面的表现,发生了翻天覆地的变化。在预测领域,有一个叫Metaculus的国际预测锦标赛,这是一个全球预测赛事,参赛者需要对60个涵盖地缘政治、体育赛事、科技动向等等事件的走向,给出概率判断。
在2025年之前,还没有任何AI,能够在这类赛事上取得名次。但2025年变了,一家名叫Mantic的伦敦初创公司,将其AI预测引擎送上赛场,在超过500名参赛者中取得了第8名,这是AI历史上的最佳战绩。几个月后的秋季杯,Mantic的模型又升级了,名次也更进一步,拿下第4名。
这个进步曲线,让人想起当年DeepMind参加蛋白质结构预测比赛CASP的历史,从最初不起眼的参赛者,到逐渐取得压倒性优势。
并且,Mantic走的还不是Multi-Agents模拟路线。它的CEO Toby Shevlane(曾任Google DeepMind研究科学家),将其描述为一种”脚手架”架构:把多个大语言模型LLM集成编排成一支团队,每个模型各司其职:一个专攻选举数据,一个扫描天气信息,一个处理经济指标,最终协作生成综合预测。”这代表了AI预测中相对直接的一条路径:不模拟人群行为,而是直接让AI阅读和处理海量信息后,输出概率判断。
这意味着,随着基础大模型推理能力的提升,即便是”多LLM集成编排”这种相对直接的路径,也已经能在最顶级的人类预测竞赛中,取得惊人的进步。而比“LLM集成编排”,更前沿的新路线——Multi-Agents模拟预测,正在以更激进的方式发展。
以Simile和Aaru为代表的新公司,是一种方法论的转变:它们不再”计算”未来,而是”模拟”未来,通过构建由成千上万个AI agents组成的微型社会,赋予每个agent人格、记忆和行为逻辑,让它们在虚拟世界中自由交互、演化、博弈,再运行成千上万次“平行宇宙”,观察哪些结果以最高概率,涌现出来。
这个赛道的终极野心,是模拟整个人类社会。
02、
什么是Multi-Agents模拟预测?
要理解这个赛道,首先需要区分三种不同层次”理解未来”的方式。
第一种是传统预测模型:读取历史样本、提取特征、拟合关系、然后对未来做外推,也就是从过去的数据中,发现某种模式,然后向未来延伸。
从2022到2024年间AI预测赛道的第一波热潮,基本都建立在这个范式之上。它的优势是数学上清晰可解释,局限则是:信息维度有限,无法建模人与人之间的交互效应,且它的基本假设是,世界虽然复杂,但仍可以被较稳定地映射成一个结果函数。
第二种是预测市场:比如在2024年美国大选中,声名鹊起的Polymarket。预测市场用真金白银来定价未来事件的概率,参与者用自己的钱投票,由此汇聚的”群体智慧”,往往比单个专家更准确。
但预测市场需要足够的流动性和参与者,且只能回答”会不会发生”这种二元问题,很难回答”为什么”。
第三种,就是我们今天聚焦的Multi-Agents模拟预测。它要做的事情不太一样,它关心的不是单点映射,而是过程生成。
如果把一群带有偏好、记忆、人格、信息摄入路径和社会关系的agents,放进一个环境里,当有新闻、政策、价格变化、广告推广、竞品动作、甚至一场突发事件进入系统后,这些agents会如何反应?他们彼此之间如何传播?哪些情绪会扩散?哪些立场、阵营会形成?最后又会涌现出怎样的宏观结果?
这套思路的雏形,在2023年”斯坦福小镇”的论文里已经很清楚:研究者搭建了一个像素风的虚拟小镇,放入25个AI agents,让它们在其中生活、自发组织活动,所有社交行为都是自然涌现出来的。

“斯坦福小镇”的最初形态,来源:论文:Stanford University:Generative Agents-Interactive Simulacra of Human Behavior
在后续2年间,斯坦福团队进一步将这条路线推向”真实人类模拟”:从25个虚拟角色,扩展到了1052个真实个体的数字孪生。验证结果令人印象深刻,这些数字孪生在多项社会科学测试中,展现出了高度逼真的行为复现能力。
所以,这个赛道表面上看是在做预测,实质上更接近是在给社会建模:把”人怎么想”、”人会怎么选”、”人如何彼此影响”,从过去只能靠问卷、统计和专家判断的软变量,变成一个可以在机器里反复运行的系统。
Simile联合创始人、斯坦福教授Percy Liang,提供了一个理解这个新范式的精准框架。他认为,在AI发展的脉络中,我们已经经历了”预测时代”(训练通用模型来分类文本和图像),还有”推理时代”(让模型解决数学、编程等复杂多步骤问题)。
但现实世界中那些最棘手的问题——”如果我们的组织允许远程办公,生产力会怎样变化?”、”如果我们重新设计三年级数学课程,数百万学生会如何反应?”、”如果医生按照团队成果,而非个人表现来考核,会对医院产生什么影响?”
这些问题的答案,取决于许多人在时间推移中互动的涌现结果。要想回答这些问题,就需要让AI进入模拟时代——”如果当初做了不同选择,会发生什么?”
这是传统预测模型和预测市场都无法触及的维度。所以Polymarket是一种市场型预测,而Multi-Agents模拟预测,是生成型预测。
当然,二者并非不能融合。一个在未来很可能发生的情况是:Multi-Agents模拟预测,负责生成更细腻的机制洞察和条件分布,预测市场负责在真实资本约束下做最后校准。一个像”推演引擎”,一个像”结算引擎”。前者回答”在什么条件下会发生什么”,后者回答”市场最终把概率压到多少”。
不过,Multi-Agents模拟的概念,也并不新鲜,其实在学术界已讨论多年,为什么偏偏在2025、2026年开始升温?最关键的变量是算力成本。
3年前,百万级Agent模拟,还是纯学术幻想,成本高到离谱。今天LLM推理成本已经降了大约50倍,MIT AgentTorch用原型聚类实现了840万Agent模拟,每步成本才0.1-0.2美元。按现在这个成本下降速率,18个月后还会再掉一个数量级。所以我们判断这个赛道的锚点,不是”现在够不够成熟”,而是”成熟的速度有多快”,毕竟你今天觉得不靠谱的场景,明年可能就靠谱了。
对于未来的Multi-Agents模拟预测来说,说个不太严谨但很传神的类比:这东西本质上是一种全新的认知工具。以前人类理解未来,要么靠方程(天气预报、金融模型),要么靠问人(问卷、访谈、焦点小组)。方程处理不了人类的非理性和”传染性”,问人又捕捉不到群体互动产生的二阶效应,比如一条谣言是怎么从三个人变成三百万人的。
而它第一次提供了一种可能:让百万个”有记忆、有人格、会互动”的AI,在虚拟环境里自主演化,然后你站在上帝视角看结果。这已经不是对现有工具的升级,而是一个新品类,有点像望远镜之于天文学,显微镜之于生物学。当然,望远镜刚发明出来的时候,也被当成了好一阵子的”好奇心玩具”。
03、
市场有多大?赛道里都有谁?
如果只把这件事理解成“市场调研的AI替代品”,会低估它很多。
当然,有可能最先被打穿的,确实是市场调研行业。a16z在2025年的一篇研究中指出,全球市场调研行业,每年支出高达1400亿美元,而其中绝大部分都花在了传统方法上:耗时数月的问卷调查、昂贵的焦点小组、以及动辄数百万美元的咨询报告。传统人力密集型咨询巨头如Gartner和McKinsey,都属于这个市场。
用AI模拟,给了企业一条更快、更便宜的捷径。
我们研究了这个赛道30多家创业公司的模式,按照目标的从小到大,大致可以总结3个方向的分化:
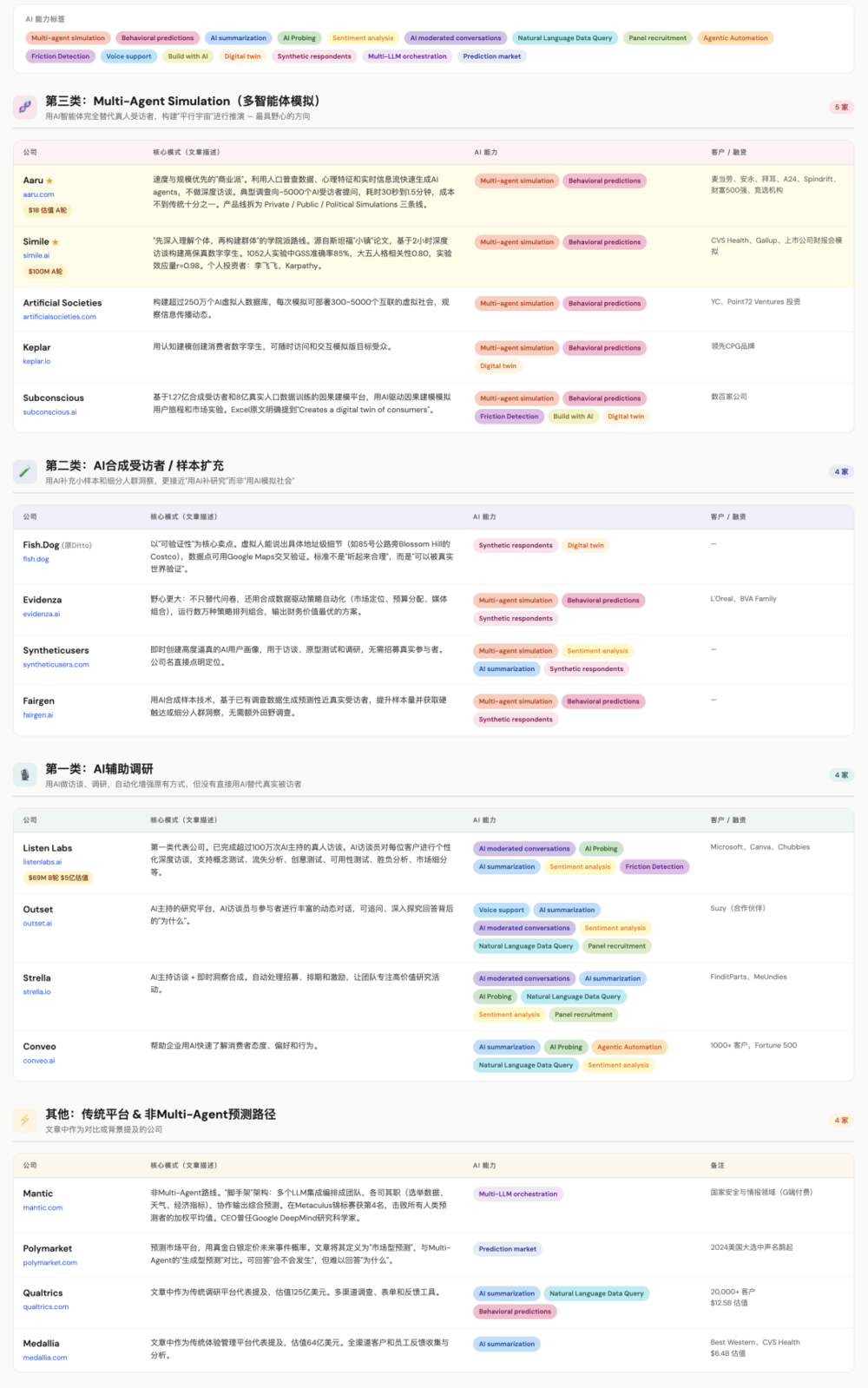
数据生成:Claude Code
第一类是AI辅助调研。这类公司用AI来做访谈、调研,通过自动化流程增强原有调研方式,但没有直接用AI替代真实被访者。代表公司是Listen Labs,已完成超过100万次AI主持的真人访谈,2026年1月获得6900万美元B轮融资,估值5亿美元。类似方向的还有Outset、Strella、Conveo等。
第二类用AI合成受访者,用于样本扩充。AI的作用,主要是为了补充小样本和细分人群洞察,典型例子包括Fish.Dog、Evidenza、Synthetic Users、Fairgen等等。它们更接近”用AI补研究”,而不是”用AI模拟社会”。
比如Fish.Dog(原名Ditto),就将”可验证性”作为核心卖点,在一个演示中,它们的虚拟人不只知道”圣何塞人去Costco购物”,而是能说出”我去的是85号公路旁Blossom Hill的那家Costco,然后会顺路去Monterey公路上的墨西哥小超市买香菜,因为价格更好,收银员会自然地切换到西班牙语”,这些数据点都可以打开Google Maps交叉验证。合成调研的标准不应该是”听起来合理”,而应该是”可以被真实世界验证”。

谷歌卫星地图验证:位于圣何塞蒙特雷高速公路旁的加州市场内部,地点、细节与虚拟人物描述一致,这反击了对虚拟人物用于调研的常见批评——“它们不过是语言模型罢了,仅仅是基于训练数据,生成在统计学上看似合理的文本,但其实对现实世界一无所知,也无法提供任何超出普通GPT封装工具所能提供的信息。”;来源:FishDog
Evidenza的野心更大:不只替代问卷,而是用合成数据,去驱动从市场定位、预算分配、媒体组合等等的策略自动化。Evidenza的终极目标是运行数万种策略排列组合,最终输出财务价值最优的方案。
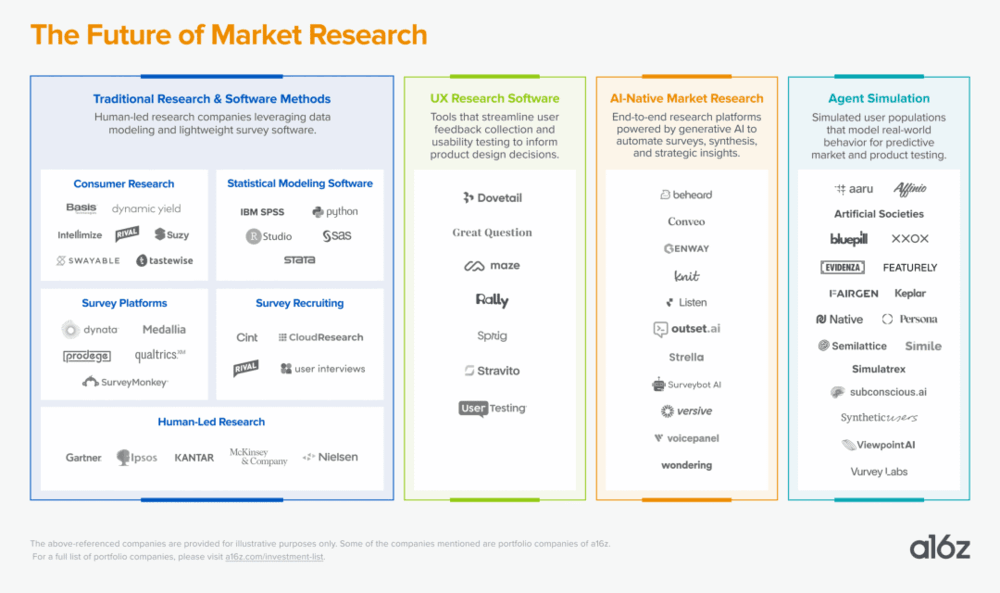
a16z判断的未来市场调研赛道;来源:a16z(2025)
第三类就是Multi-Agents Simulation(多智能体模拟),这也是最具野心的。这些公司试图用AI智能体完全替代真人受访者。
代表公司包括估值10亿美元的Aaru(用公共和私有数据生成智能体,强调速度和规模)、获1亿美元融资的Simile(基于真人深度访谈构建高保真数字孪生,强调精度和可验证性),以及Artificial Societies(构建了超过250万个AI虚拟人的数据库,每次模拟可部署300到5000个互联的虚拟社会,来观察信息传播动态,获YC和Point72 Ventures投资)、Keplar(用认知建模创建消费者数字孪生)、Subconscious(基于1.27亿合成受访者和8亿真实人口数据,训练出来的因果建模平台)等十余家公司。
但Multi-Agents模拟预测的潜在应用,远不止市场调研。数字营销与广告效果预测(全球数字广告市场超7000亿美元)、选举民调与政治咨询、企业战略决策与情景推演、金融市场情绪分析、政策模拟与公共管理等等。
特别是在国家安全与情报领域,AI预测也越来越引起关注。顶尖人类预测(比如兰德公司)的产出极其昂贵且缓慢,而一个可靠的AI预测器,可以同时追踪数百个问题、持续更新判断。前文提到的Mantic,目前主要场景就是国家安全与情报,主要靠G端付费(不过Mantic并不算Multi-Agents,而是多LLM集成编排)。
总之,任何需要理解和预测”人类集体行为”的场景,都是这个赛道的潜在市场,可以说是一整套”事前决策基础设施”。
当然,现在市场还充满分歧,最核心的就是一个根本性问题:虚拟人能否真正替代真人?Multi-Agents Simulation是最激进的押注;而另两类公司,则走了一条更渐进的路线,它们认为AI应该增强、而非取代人类的参与。
这场争论目前远未尘埃落定,但风投已经开始下注。
04、
两条路径:Simile与Aaru的深度解读
目前整个市场里,融资最猛、声量最大的两家公司,是Simile与Aaru,它们有很高的估值、或者有大牛坐镇。
虽然它们俩都属于Multi-Agents Simulation(多智能体模拟)这个最核心、也最具争议的方向,但代表了两条不同的技术路径,理解它们的差异,是理解整个赛道的关键:
4.1、Simile——”先深入理解个体,再构建群体”的学院派路线
Simile的故事要从2023年一篇轰动AI学界的论文说起。那一年,斯坦福大学博士生Joon Sung Park和导师Percy Liang、Michael Bernstein等人,发表了《Generative Agents:Interactive Simulacra of Human Behavior》的论文,也就是”斯坦福小镇”,在这个像素风的虚拟小镇中,放入了25个AI智能体,每个智能体被赋予一段背景故事,咖啡店老板、药房店员、大学生,然后研究者观察它们会做什么。
结果令人惊讶。当其中一个智能体被设定”想要举办一场情人节派对”后,其他智能体开始自发传递邀请、结识新朋友、互相邀约、并在正确的时间出现在正确的地点。没有人编程让它们这样做。所有社交行为都是从”记忆流-反思-规划”这一架构中自然涌现出来的。这篇论文获得了ACM UIST最佳论文奖,也成为AI智能体研究最具影响力的成果之一。
2024年11月,团队将这一架构,从25个虚拟角色,扩展到了1052个真实个体。他们招募了一个在年龄、性别、种族、地区、教育程度和政治倾向上,具有美国代表性的样本,每人接受了长达两小时的深度语音访谈,平均产生约6500词的访谈记录。
然后,这些记录被注入大语言模型,为每个人创建了一个”生成式智能体”——一个可以像那个人一样思考和回答问题的数字孪生。
验证结果令人印象深刻。在社会科学领域最广泛使用的通用社会调查(GSS)上,这些AI智能体,预测真人回答的归一化准确率达到了85%。而作为对照,真人自己两周后,重新回答同样的问题,自身一致性也不过81.25%。
在大五人格测试上,归一化相关性达到0.80。在五项经典社会科学实验的复制中,智能体与真人的实验效应量相关性,高达r=0.98。
更重要的是,基于深度访谈构建的智能体,在各维度上都显著优于仅基于人口统计描述或简短人设的智能体。前者的准确率,领先后两者14到15个百分点。这意味着:你越深入地理解一个人,你创建的数字孪生就越逼真。
从Simile公布的论文来看,它构建一个人(更时髦的说法:蒸馏一个人),基本上是四个视角:心理学家视角(人格、动机、自我决定需求)、行为经济学家视角(财务决策、风险偏好、生活满意度权衡)、政治学家视角(意识形态、政党认同,及其中的矛盾和混合性)、人口学家视角(职业、收入、家庭结构、社会流动性)。
而从数据丰富度上,有三层对比实验,证明了”理解越深,数字孪生越准”这个递进关系:
第一层:人口统计描述(最浅):仅给出年龄、性别、种族、政治倾向。归一化准确率0.71。
第二层:人设描述(中等):让参与者写一段自我介绍,包括个人背景、性格和人口统计信息。归一化准确率0.70。
第三层:深度访谈(最深):2小时的半结构化访谈,采用American Voices Project的访谈脚本,涵盖:人生故事(童年、教育、家庭与关系、重大人生事件)、对当前社会议题的看法(种族、经济等)、社会/政治/个人价值观。归一化准确率0.85。
2026年2月,这支团队走出隐身状态,正式对外亮相。CEO Joon Sung Park,首席科学家Percy Liang(斯坦福计算机科学副教授,”基础模型”一词的提出者,斯坦福基础模型研究中心CRFM的创始人),CPO Michael Bernstein(斯坦福计算机科学副教授),加上负责商业化的CCO Lainie Yallen(Hebbia早期员工,曾帮助将其营收做到15倍增长)。
Simile的产品已经在多个场景中投入使用。比如CVS Health(美国最大的药妆店连锁企业),正在使用Simile构建数十万客户的模拟,用于测试新产品、新店面布局和新概念,CVS Health拥有9000多家门店,一个错误的货架决策成本巨大。
Gallup,这家历史悠久的民调机构,已经在与Simile合作,创建数字人副本,当真人受访者因为各种原因无法联系时,数字人副本可以作为替代。
还有一个神奇的用例是,Simile还可被用于上市公司的财报电话会模拟,你可以输入历次财报电话会的所有数据,并以此构建提问分析师的AI Agents,预测它们在下一次财报会上会问什么问题。Simile声称,平均可以预测到10个提问中的8个,并能模拟CEO和CFO在不同应对策略下的对话走向,企业可以在真正召开财报电话会之前,反复”排练”。
Joon在TBPN播客(最近TBPN被OpenAI收购了)中透露了一个有趣的细节:他自己在参加这次播客采访前,就用Simile模拟了主持人可能的提问方向,以便更好地准备话题。”你们中有几位在网上非常知名,”他说,”所以我们的确可以模拟出,你们的采访将会如何展开。”
这或许是”模拟无处不在”最生动的自证。
Joon Sung Park,co-founder and CEO of Simile;来源:TBPN
4.2、Aaru——速度与规模优先的”商业派”
如果说Simile走的是”先深入理解个体,再构建群体”的学院派路线,Aaru则选择了一条截然不同的道路:不做深度访谈,而是利用人口普查数据、心理特征数据、实时信息流,来快速生成AI Agents。
比如在美国大选民调场景下,Aaru的方法是这样的:使用人口普查数据,复刻不同选区的选民,再给每个智能体,分别赋予数百种人格特征,从个人抱负到家庭关系。再注入实时信息流,这些智能体可以持续”浏览”互联网,就像它们所复刻人类的媒体消费习惯一样,阅读什么报纸、看什么网站和电视台,这有时会导致它们改变偏好。

典型的一次调查,会向大约5000个AI受访者提问,耗时30秒到1.5分钟,成本不到传统人类调查的十分之一。
这种速度优势,在商业场景中极具吸引力。当气泡水品牌Spindrift需要评估苏打水、茶饮、能量饮料和冰沙等新品概念时,Aaru详细构建了目标人群:家庭年收入超过10万美元的25至35岁消费者,不到一周就选出了果茶作为最佳方向。
而Spindrift的传统消费者调研,得出同样结论花了两个月、涉及500人。Spindrift最终推出了一系列非碳酸冰茶新品。
安永也在尝试使用Aaru,来进行高净值客户调研。安永的项目,是要复现一项针对3600名高净值投资者、覆盖30多个市场、历时一年的全球财富研究报告。Aaru在一天之内完成,中位相关度超过90%。
更值得关注的是,在AI模拟与传统调研出现分歧的地方,AI模拟反而更准确地预测了真实行为,比如82%的家族继承人,在传统调研中声称会保留父母的财务顾问,而AI模拟预测的留存率是43%,但现实数据显示,实际留存率只有20%到30%。
人类有时在调研中会说谎,无论是有心的还是无心的,记忆失准,或是在社会压力下,扭曲真实想法。这也是最近几年美国大选中,传统民调机构屡次失败的核心原因,而这正是Aaru的核心价值。
Aaru的产品线已经很丰富,不只服务企业调研,而是拆成了Private、Public、Political Simulations三条线。用户可以配置不同的新闻、事件和信息世界,再去预测不同人群,在特定条件下会如何反应。Aaru的客户已经覆盖了一些财富500强公司、竞选机构和智库。
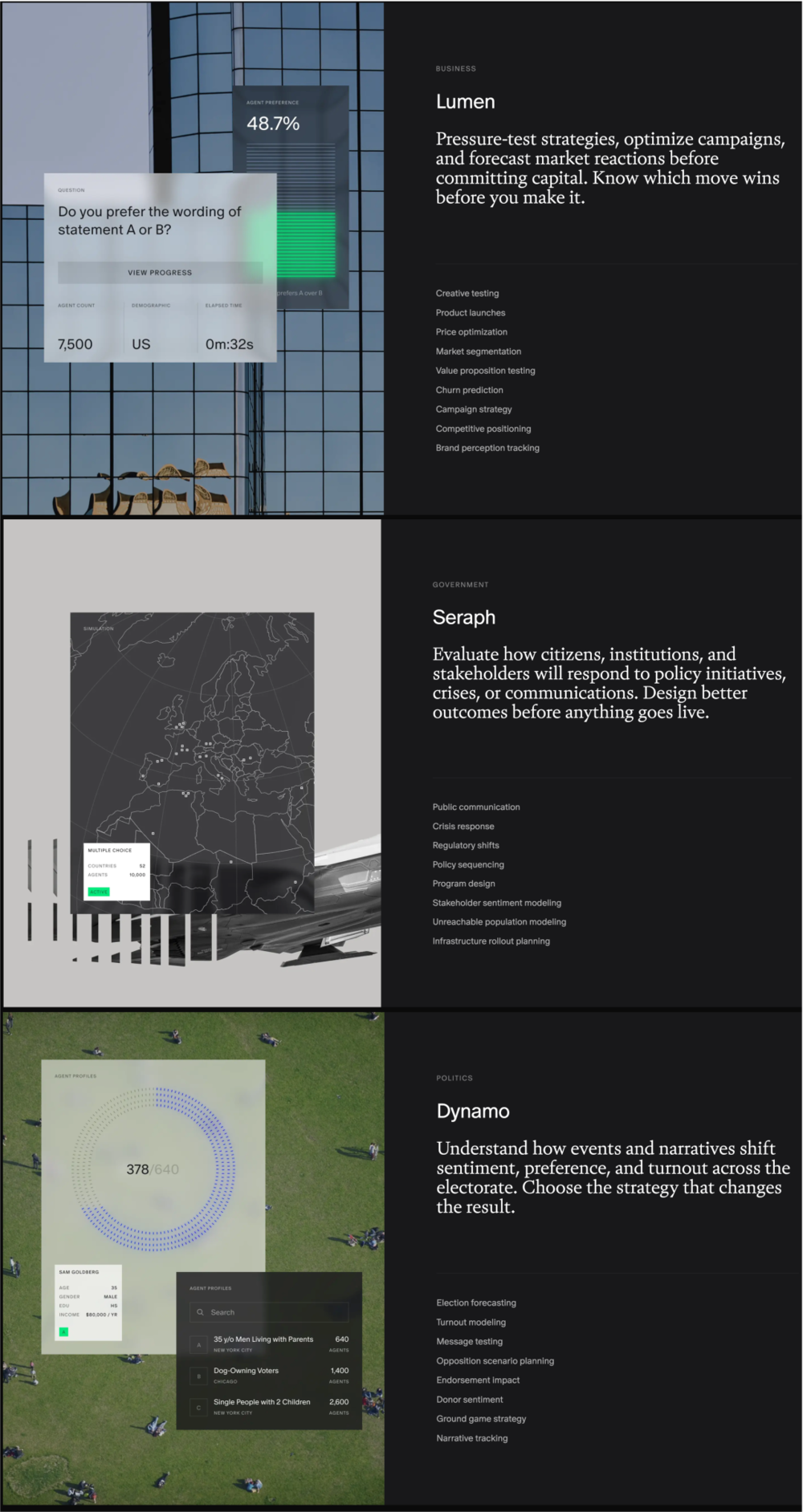
Aaru的三大产品线;来源:Aaru
如果Aaru的产品在未来能更加成熟,那应用边界就会天然外溢到数字营销、创意测试、产品概念验证、定价策略、客户流失预判、财富管理、财报电话会预演、政策推演、选举民调、议题传播、公关危机测试,甚至更广义的组织行为模拟。
这也是这个赛道真正想卖的:不是”一个更便宜的问卷调研工具”,而是”一个在决策之前,先跑一遍世界的模拟器”。
不过,Aaru目前还不够成功。在政治预测方面,Aaru在2024年美国大选中,公开测试了一轮。在纽约民主党初选中,预测的结果还算准确,但对川普还是哈里斯胜选的最终答案,依然预测错了,当然可能比民调机构的票数误差,要稍微少那么一点。
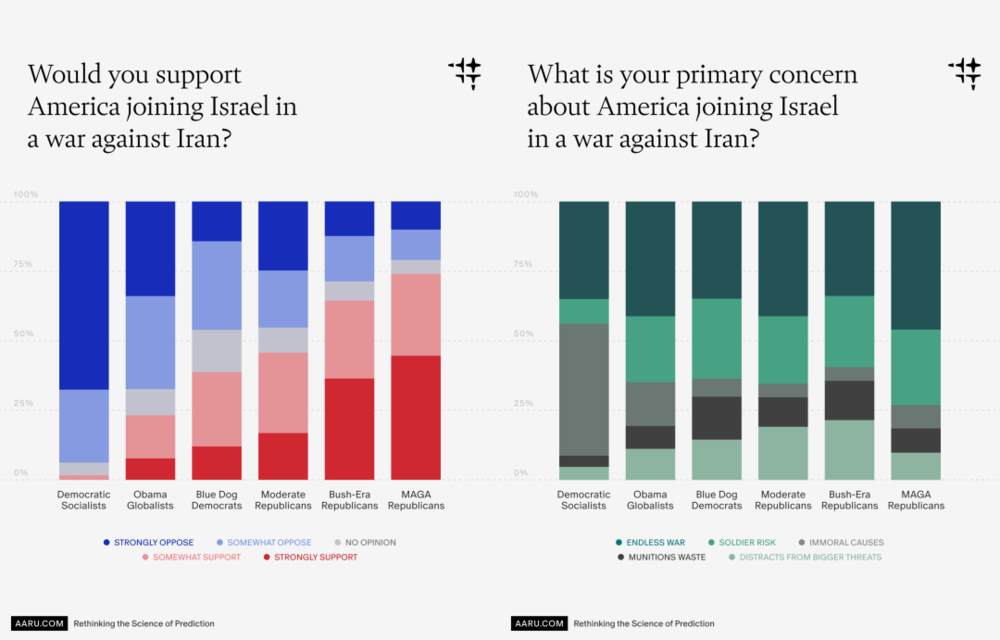
Aaru最新的虚拟调研:对美国不同政治派系,在”是否支持美国加入以色列对伊朗的战争”这一议题上的态度预测。来源:Aaru
4.3、两条路径的核心差异
Simile和Aaru的路径差异,是一个关于”什么数据才能让AI真正理解人类”的分歧。
Simile认为,你必须深入访谈真人、获取丰富的个体层面数据,才能创建足够逼真的数字孪生。斯坦福的实验在一定程度上证明,基于深度访谈的智能体,要优于仅基于人口统计和性格数据的智能体。
Aaru则认为,你不需要真人参与,行为结果数据和实时信息流,就足以校准模型,他们称之为”ground-truth training”,用真实世界中可测量的行为结果,而非人们自我报告的态度,来做锚点。
在采访中被问及护城河时,Simile联创的回答,揭示了Simile对自身差异化的理解:他们构建的不是超级理性的智能,而是模拟人类”非理性的那一半大脑”——价值观、偏好、品味。
大模型优化的方向,是让AI变得更聪明、更理性;Simile优化的方向是让AI更像人,包括人类的犹豫、矛盾和非理性。
我个人有个判断:现在这两条路径,3-5年后大概率会合流。道理很简单,宏观事件归根结底是无数个人决策的汇总涌现。Simile从”精确理解个体”切入,理论上完全可以往上延展到宏观推演;Aaru从”规模和速度”切入,迟早也需要理解驱动宏观结果的微观行为机制。差别只是从哪一端开始跑、谁先跑通,几年后它们很可能在同一个战场上正面撞上。
05、
护城河是什么?
虽然这个赛道的发展还很早期,但我们也很关心成功的要素会是什么,目前来看至少有四层。
第一层是数据壁垒。尤其对Simile而言,关键不是有多少公开文本,而是有没有经过授权、可持续更新、可做行为校准的深度访谈,也包括购买的二手数据、调研而来的一手数据、真实回应的历史数据等等。像CVS Health那种,有290万条回答、40多万真实人类许可的数据资产,就是别人短期内很难复制的护城河。
第二层是拟人精度。不是让agent”说”得像人,而是让它在问卷、权衡博弈、连续交互里,都能稳定复现真实个体的行为。Stanford那套1052人实验的意义,就是给”数字人到底如何才能像人”,建立一个可以检验的框架。
第三层是多智能体体系构建。让单个agent输出一段像人的文本并不算太难,真正难的是让上千上万agents,在同一个环境里长期运行,不爆内存、不跑偏、不因为小bug产生荒谬行为,同时又保有记忆、目标、约束和关系传播。
第四层是技术与产品的融合能力。这个领域要想成功,不能仅有研究突破,还需要知道怎么把产品化,如何让企业愿意采购。比如Simile反复强调自己的一个优势是,他们的团队同时在模型前沿和产品前沿,而更好的模型,直接意味着更好的结果。
这不是每个AI创业公司都能有的,Simile的团队,是由三位斯坦福AI前沿研究者,加一位商业化操盘手,以及著名的个人投资者李飞飞和Andrej Karpathy。对比之下,Aaru的组合是三个不到20岁的天才少年,加上知名民调专家Frank Luntz等行业顾问,代表了另一种”速度+商业直觉”的风格。两种模式谁能走得更远,现在还远未可知。
我们最关心的瓶颈,说实话不是技术,是验证闭环。这个赛道有个很别扭的特性:你要验证一个预测准不准,得等事情真的发生了才知道。这意味着反馈周期天然很长,数据飞轮转得很慢。更要命的是,这个方向真正的价值是预测”没发生过的事”,比如一项新政策出台后社会怎么反应、一个新产品上线后用户怎么选,而这些”没发生过的事”,你永远没法提前证明模拟是对的。所以谁先设计出更短的验证闭环,谁就拿到了这个赛道的领先武器。
06、
冷水时刻:这个赛道的问题与质疑
整体看好不意味着无视问题。事实上,围绕Multi-Agents模拟预测的质疑声音,同样强烈,这也是迷人的非共识之处。
6.1、选举预测的翻车——最刺眼的压力测试
2024年11月美国大选前,Aaru公开发布了对七个摇摆州的预测,总体预测哈里斯赢下密歇根、内华达、宾州、威斯康星四个关键州而胜选。但实际结果是川普横扫全部七个摇摆州,Aaru的预测大面积失准。
联合创始人Fink为此辩解,AI预测的结果比传统民调误差更低,当然这也是因为传统民调机构错的更离谱,但AI更快更便宜。
可口可乐开放式创新总监Ashlee Adams也坦承,业界对这个方法,能否比真人调研提供更准确的洞见,仍然存有疑虑。
当然这也许是2024年11月,模型技术本身还没有今天这么成熟,别忘了大模型迭代速度非常快。

在2024年美国大选前,有一篇论文主要用GPT-4o(基于多步推理框架V3 Pipeline),进行了美国大选预测,模型给出特朗普268票、哈里斯259票的结果。模型未纳入实时舆情和人口动态变化等因素,这构成了主要局限。虽然最终结果正确,但对特朗普最终的胜选幅度严重低估,并且对一些关键摇摆州预测偏差明显。总体来看,模型存在明显的偏向民主党的系统性偏差,论文也提到了GPT-4o存在自由派倾向,导致对共和党的支持率被系统性低估。来源:USC,Arima,CMU:Will Trump Win in 2024?Predicting the US Presidential Election viaMulti-step Reasoning with Large Language Models
6.2、对合成样本的系统性批判
对AI民调最尖锐、也最有实证支撑的批评,来自民调专家G.Elliott Morris。Morris与民调公司Verasight合作,进行了一项严格的基准测试:为1500名真实美国成年人,创建了一个”数字孪生”(基于性别、年龄、种族、教育程度、收入、居住州、意识形态和党派性),然后要求模型,像那个人一样回答同样的问题。
结果令人警醒。
在总体层面,大模型对川普支持率,和国会通用票选的预测,与真实人口比例的误差,在4到23个百分点之间。即使是表现最好的模型,也高估了川普的反对率。在人口亚群层面,误差进一步放大:关键群体如黑人受访者的误差,高达15个百分点,亚裔及太平洋岛民群体误差,达到惊人的30个百分点。
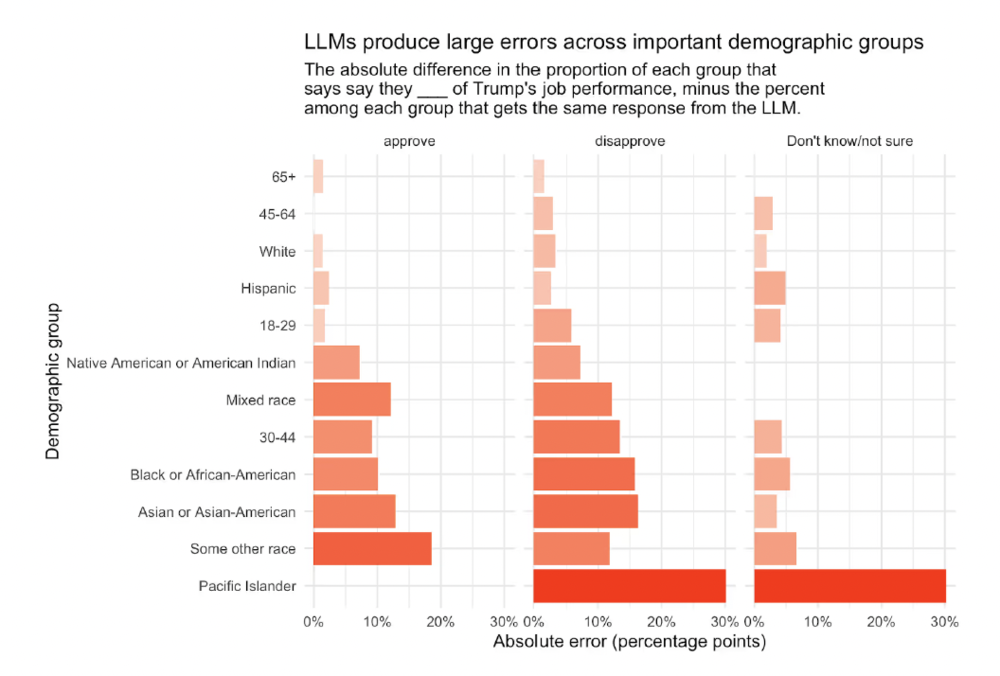
针对少数族裔的误差很大。来源:Your Polls On ChatGPT,By G.Elliott Morris and the Verasight data team
并且,真实受访者中,有近3%选择了”不知道”(这代表了约800万美国成年人),但AI模型几乎从未给出过这一回答。而人类的不确定性,也是政治态度的重要组成部分。Morris认为,AI之所以消除不确定性,是因为它从根本上,不是被训练来模仿人类大脑的,它是被训练预测文本序列中的下一个词。
所以Morris的结论是:你可以询问一个人对政治问题的感受,你不能对机器人这样做。
这里我想顺便说一个反直觉的事:在Agent模拟这件事上,小模型可能比大模型更好用。经过大量RLHF对齐的大模型,在模拟人类行为时会出现一种”模式坍塌”,也即所有Agent倾向于给出差不多的”正确”回答,把人类群体天然的多样性和非理性给抹平了。
有研究表明,2个真正有差异的Agent,效果能超过16个同质Agent。更小的、对齐程度更低的模型,反而更容易被不同的人物设定所塑造,产生更真实的行为分化。这暗示了一件对投资来说很重要的事:这条赛道的技术路线,和主流”追求更大更强模型”的方向也许是分叉的。它不需要最聪明的模型,它需要最多样的模型。也就是说,大模型公司不太可能顺手就把这事给做了,独立创业公司有自己的生存空间。
6.3、来自Simile团队自身的审慎警示
值得特别关注的是,即便是这个赛道中最具学术严谨性的团队,也在主动呼吁审慎。
Simile的研究者在论文中,明确指出了三类风险:决策者可能在模拟精度不足时错误信任结果;构建智能体所需的访谈数据高度敏感,泄露或篡改可能造成严重声誉伤害;以及模拟已故人员、知情同意管理、智能体被用于欺诈等一系列伦理灰色地带。
所以Simile不向公众开放其智能体库,仅提供受控的研究用API访问。他们还提出了为智能体库中,每个智能体建立审计日志的方案,让参与访谈的个人,可以看到其数字孪生在做什么,并在任何时候撤回授权。
Simile还直言不讳地建议,要”谨慎审视那些,过度声称AI当前预测能力的分析”。
此外,来自达特茅斯学院发表的论文,还提供了另一个令人不安的视角:AI可以大规模腐蚀公众意见调查。在2024年大选前的7次主要全国民调中,只需注入10到52个虚假AI回答,每个成本仅5美分,就有可能翻转民调预测结果。
这意味着一个讽刺性的悖论:用AI模拟取代人类调研,与AI污染人类调研,竟是同一枚硬币的两面。
07、
终局会走向哪里?
Aaru在其白皮书中写道:”两年内,我们将模拟整个地球——从乌克兰的农作物种植方式,到其如何影响伊拉克的石油生产、马六甲海峡的贸易,以及巴尔的摩市长选举。”
Simile CEO Joon Sung Park在采访中则更加直白:”如果我们能创建80亿人的模拟,也就是整个地球,那意味着什么?这就是我们正在走向的未来。”
Joon引用《黑客帝国》中The Oracle(预言先知)的那句话,或许最能捕捉这个赛道的哲学:”你来这里不是为了做决定——你已经做了决定。你来是为了理解这个决定,以及你为什么做了它。”
模拟的价值,不仅在于预测未来,更在于理解当下:创建可以追溯、验证的”社会运行日志”,让我们理解复杂系统为什么会走向某个结果。
当然,对于任何想入局的创业团队来说,我们觉得最该回答的问题不是”能不能模拟百万Agents”,而是”你到底在给谁解决什么问题”。
这个方向目前存在两条完全不同的方向:一种是严肃工具(政策模拟、舆情预测、企业决策辅助),另一种是体验产品(让普通人围观甚至参与Agent社会的演化)。两条路对团队的要求完全不同,混着做大概率两边都做不好。历史上看,真正有持久价值的往往是工具路线(从Bloomberg Terminal到Palantir),但它们的成熟周期都在十年以上。而体验路线容易出圈,但也容易速朽。
此外,在兴奋之余,一个结构性的鸿沟也就在眼前:目前所有的模拟,都建立在大语言模型之上,是在”文本层面”的人类行为模拟。
但人类社会还有大量物理层面的交互:空间移动、物质消耗、身体接触、环境约束。Joon本人也承认这一点:如果要创建整个世界的模拟,就需要”不仅建模人,还要建模环境和整个世界”。
这就需要”世界模型”(World Model)的重大突破,创建一个能够理解和模拟物理世界因果关系的AI。可是世界模型现在仍处于极早期阶段,各大实验室(从Meta的V-JEPA到Google的Genie)都在探索,但距离可用还很遥远。这意味着”模拟80亿人”的宏大愿景,在技术上还需要漫长的等待。
今天的Multi-Agents预测,或许更像是1990年代的互联网:底层技术在快速进步,商业需求真实存在,先行者已经开始赚钱,但距离实现它的终极承诺还很遥远。
这个赛道最大的机遇,不在于能否完美预测未来,而是在真实世界试错之前,先在数字世界中预演一千次。
而它最大的风险,也恰恰在于此:当我们越来越依赖”预演”来做决策时,我们是在更好地理解世界,还是在用一面精美的镜子取代了窗户?
#当10亿个AI一起模拟未来李飞飞和Karpathy共同押注的新赛道