半导体行业观察:上限看端侧,下限看Q布,由光入布好。

<
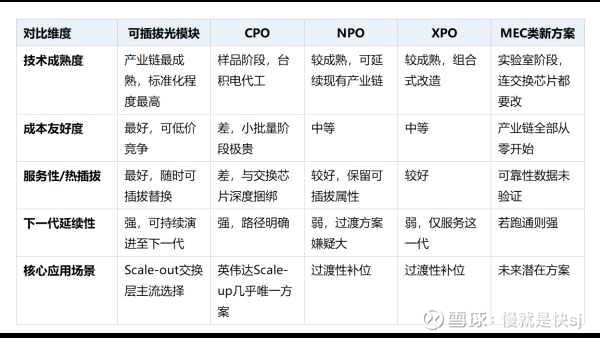
光通信产业正在进入史上最混乱的一年。过去四十年"四年翻倍"的光模块技术迭代节奏,被3.2T时代硬生生打断——单通道400G信号在光模块到交换芯片之间十几厘米的距离上难以保真传输,直接导致可插拔光模块、CPO、NPO、XPO以及基于新型光电器件的MEC类方案五条赛道同时起跑、争夺下一代市场份额。但更重要的是,整条供应链真实信号被严重失真:EML芯片、CW激光器、InP衬底等上游核心物料普遍出现"超量下单",越往上游放大倍数越大,磷化铟(InP)衬底当前订单总量已达头部供应商产能的4-5倍。与此同时,200G EML芯片全球仅Lumentum与II-VI两家能稳定量产、400mW高功率CW激光器仅Lumentum一家可规模供应;OCS交换机核心MEMS与LCD器件供应格局高度集中,谷歌短期内不会引入第三家供应商。多条技术路径各管一段、真实需求与表观订单严重背离——这场混战的真正胜负手,藏在场景与上游物料的交集里。
类似于3G向4G过渡期间的小灵通——参数看起来可以用,但一旦下一代主路径跑通,过渡方案的整条产业链就会被快速边缘化。NPO与XPO当前面临的最大风险,恰恰是这种"临时方案"属性。而可插拔与CPO之间则更像"各打各的场景":前者守住scale-out交换层,后者锁死英伟达scale-up的封装内空间,并非简单的你死我活。
![]()
![]() 被放大了5倍的订单信号:超量下单正在扭曲真实需求。
被放大了5倍的订单信号:超量下单正在扭曲真实需求。
这是今年光通信产业链最被忽视、但可能最重要的一件事。
在上游紧缺向下游传导的过程中,每一层客户都倾向于"多报一点、以防缺货"——这就是典型的牛鞭效应。越往上游,放大倍数越大。产业专家给出的量级非常直接:100G EML的实际真实需求与供给基本匹配,但表观订单里至少叠加了2-3倍的过度下单;到了最上游的磷化铟(InP)衬底环节,当前订单总量已达住友、AXT等主要供应商产能的4-5倍,交货期被拉长至大半年到一年以上。
这个信号有两重含义。一方面,真实终端需求的强度可能并没有表观订单显示得那么夸张;另一方面,一旦某一环节真实产能释放、或AI数据中心资本开支节奏出现变化,越上游的环节越容易出现订单"突然消失"的剧烈波动。对于研究产业链的人来说,必须把表观订单与真实终端需求分开看——这不是周期性数据的噪声,是结构性现象。
![]()
![]() 上游真正锁死节奏的三个环节
上游真正锁死节奏的三个环节
① 200G EML芯片:全球仅两家能稳定量产。100G EML有六家能做(Lumentum、II-VI/Coherent、博通、住友、Source Photonics、索尔斯,其中索尔斯算半个国产),但到了200G档位,目前能真正大规模量产的仅有Lumentum和II-VI两家,且良率偏低。下游头部模块厂商拿不到足够货源,大量转向硅光方案作为替代,进一步推升了CW激光器的需求。
② CW连续波激光器:高功率档位高度集中,但这是全链条最强确定性环节。70-100mW CW(配套硅光1.6T模块)供给相对多元,Lumentum最强、住友可做;但400mW高功率CW——这是CPO方案必备的光源——目前仅Lumentum一家能规模供应。CW激光器在整个光互联产业链中具备最清晰的"跨赛道确定性":无论最终哪条技术路径胜出(可插拔、CPO、NPO还是XPO),只要是硅光方案,都需要外置CW激光器。这使它成为少数不依赖赛道胜负判断的环节。
③ 磷化铟(InP)衬底:受中国稀土管制显著影响。衬底是磷化铟外延片的底材,全球主要供应商是住友(大头)与美国AXT/通美(小头);当前4寸衬底价格已推升至数百到上千美元水平,供应商产能虽翻倍扩张,但仍远不能满足订单需求。关键变量是——磷化铟中的"铟"属于中国出口管制范围内的稀土金属,这意味着日本住友在供应稳定性上受到的约束显著强于欧美供应商,中美贸易摩擦的非对称性会进一步放大这一差异。
此外,DSP芯片(马维尔、博通主导)、硅光片(Coherent与住友-三菱合资公司Go!Foton主导,国内厦门、成都、福州合计市占约7-8%),以及资深光模块工程师的人才储备,是并列的产业链约束项——后者常被忽视,但没有足够工程师,产能扩张本身也受限。
![]()
![]() OCS这条支线:比市场说的更集中
OCS这条支线:比市场说的更集中
顺带厘清一个常见误区——OCS(光电路交换)与CPO并不是替代或从属关系,两者可以配套使用也可以各自独立。当前OCS的规模化使用者仍然只有谷歌一家,英伟达的OCS方案预计2028年才会真正落地;亚马逊、Meta等虽然在研究,但短期内看不到大规模部署信号。
技术层面,OCS目前两条主流路线——MEMS方案(约占2/3,由Lumentum主导)与LCD方案(约占1/3,由Coherent主导)——背后真正能给谷歌供货的只有这两家,短期内谷歌不会引入第三个供应商。声称"做OCS"的公司很多,能真正供货的只有这两家。压电陶瓷、硅光波导等路线虽然速度更快(从毫秒级提升至微秒级),但成熟度还停留在实验室阶段,1-3年内难以挑战现有格局。
专家访谈:
AI 大模型狂飙的这两年,算力基础设施的形态已经彻底重构,光互联从配角一跃成为决定数据中心带宽、时延与成本的核心变量。谷歌率先把 OCS 光电路交换推向规模化商用,英伟达紧锣密鼓布局 2028 年 OCS 方案,CPO 共封装光学更是成为下一代算力集群的必争之地。这场技术迭代背后,是技术路线的激烈博弈、产业链上下游的供需失衡,还有中美供应链的隐形角力。
01|除了谷歌,其他主流云厂商在 OCS 领域的态度和进展如何?
先给大家纠正一个误区:OCS 不是什么新技术,早在上世纪 90 年代就有了,只是谷歌把它打造成了光交换机模式,才在 AI 数据中心里火了起来。目前除了谷歌这个 “绝对主力”,只有英伟达在认真规划 OCS 的应用,计划在 2028 年左右,在其 Frame 系统中考虑使用 OCS,但目前还只是初步方案,没有实质性的落地动作。
至于亚马逊、Meta(Facebook),虽然也有相关的考虑,但目前完全看不到大规模采用 OCS 的迹象。核心原因很简单:OCS 要大规模落地,离不开厂商自身的 ASIC 芯片量产—— 现在这些厂商的 ASIC 芯片,和谷歌的 TPU、英伟达的 GPU 处于直接竞争状态,相当于 “内部供应商” 和 “外部供应商” 抢市场,只有它们自己的 ASIC 芯片能在市场上站稳脚跟,OCS 才有大规模应用的可能。
总结下来就是:目前 OCS 的格局就是“一大一小”,大的是谷歌(已经规模化应用),小的是英伟达(2028 年初步规划),其他云厂商还在 “观望试探”,短期内看不到实质性进展。
02|英伟达 OCS 的开发时间线、定位是什么?和谷歌有什么区别?
很多人以为英伟达在搞 OCS 的硬件研发,其实完全搞错了 ——OCS 的硬件技术已经非常成熟,没有什么复杂的研发空间,英伟达现在的核心精力,全放在OCS 的控制软件系统上。为什么控制软件这么重要?因为 OCS 的控制信号逻辑,和传统交换机完全不一样,这也是 OCS 能不能真正落地、效率能不能发挥出来的关键。
英伟达目前主要在其 Frame 系统中,全力开发 OCS 控制软件,按照目前的进度,2028 年才会逐步推出相关方案,而且不排除后续根据技术成熟度调整方案。
和谷歌相比,两者的核心区别的在于“定位不同”:谷歌是 OCS 的 “开创者”,已经实现了规模化应用,核心是服务于自身的 TPU 集群,解决大规模算力互联的问题;而英伟达的 OCS,更多是为其 GPU 集群配套,目前还处于 “软件研发阶段”,定位是补充自身算力互联的方案,暂时没有谷歌那样的规模化应用场景。另外补充一句:有人说 OCS 效率更高、功耗更低,其实这个说法不绝对,核心还是看应用场景。
03|OCS 的主流技术路线(MEMS、液晶等)有什么差异?主流厂商推什么方案?
目前 OCS 大规模应用的技术路线只有两种:MEMS(微机电系统)方案和液晶方案,其中MEMS 方案占比约 2/3,液晶方案占比约 1/3,其他方案(压电晶体、硅光波导)还处于非常早期的阶段。先讲主流方案的主导厂商和差异,这部分很关键,能帮你避开 “蹭热点” 的厂商:
MEMS 方案:主导厂商是Lumentum(鲁门特),也是谷歌 OCS 的核心供应商。它的优势很明显 —— 可以实现大规模通道扩展,比如 32×32、64×64,甚至更大规模的通道,而且成本是线性增长的(比如 64×64 的成本大概是 32×32 的 2 倍),非常适合 AI 数据中心的大规模算力互联需求。但缺点也很突出:内部有机械移动部件(小镜子),长期可靠性较差,适合 AI 数据中心(生命周期 5-8 年),不适合电信长途干线(要求 20-28 年设计寿命)。
液晶方案:主导厂商是Coherent(考辛),也是谷歌 OCS 的供应商之一。它的优势和 MEMS 正好相反 —— 没有机械移动部件,可靠性极高,适合电信市场,但缺点是通道扩展难度大,成本呈指数级增长(比如 64×64 的成本是 32×32 的 4 倍,128×128 是 16 倍),在 AI 数据中心的大规模应用中不占优势。
这里必须提醒大家:现在很多厂商声称在做 OCS、和 OCS 合作,其实都是蹭热点,真正能给谷歌供货的,只有 Lumentum 和 Coherent 两家,短期内谷歌不会增加第三个供应商 ——OCS 是 AI 数据中心最核心的交换机,可靠性要求极高,谷歌不可能冒险选择小厂商,而且这两家还是 WSS(波长选择开关)的绝对龙头,WSS 的简化版就是 OCS,有长期的技术和品质积累。
至于压电晶体和硅光波导方案,目前基本处于实验室阶段:压电晶体切换速度快(亚毫秒级,比 MEMS、液晶快 10 倍),但可靠性没有经过大规模验证;硅光波导切换速度更快(微秒级,比毫秒级快 100-1000 倍),但损耗高、技术完全不成熟,比压电晶体还要早期。专家判断,未来 1-2 年内,这两种方案不会有太大发展。
04|OCS 交换机的成本构成是什么?哪些部件价值量最高?
先明确一个前提:OCS 交换机的软件是谷歌自己开发的,我们这里只算硬件成本。以32×32 通道的 OCS 交换机为例,硬件成本大概在10 万美元左右,如果是 64×64 通道,成本基本翻倍,和我们前面说的 “通道扩展成本线性 / 指数增长” 一致。
成本构成拆解(按价值量从高到低):
核心交换单元(MEMS 芯片或液晶阵列):这是最核心、价值量最高的部件,占硬件成本的20% 左右(按 10 万美元硬件成本算,大概 2 万美元)。如果是 MEMS 方案,核心就是 MEMS 芯片;如果是液晶方案,核心就是液晶阵列,这两个部件直接决定了 OCS 的性能和可靠性。
人工组装成本:这是很多人忽略的点,OCS 的人工组装成本占比非常高,大概20-30%。因为 OCS 的通道需要精准调光、定位(行业内叫 alignment),比如 32×32 通道就有 64 个通道,每个通道都要调试、固定、固化,还要做高低温测试,确保不会损坏,工作量极大,不像光模块那样可以自动化生产,人工成本自然居高不下。
光端口相关部件:包括透镜、FAU(光纤阵列单元)、支架、尾套(防止光纤折断)等,价值量较低,技术难度也不大,占硬件成本的比例不高。
总结下来:OCS 交换机的成本核心是 “核心交换单元 + 人工组装”,这两个部分占了硬件成本的一半以上,也是后续成本优化的关键。
05|OCS 核心交换单元的上游供应链是什么?主要供应商有哪些?
这个问题专家也坦诚,部分细分供应商他也需要会后核实,但核心供应链和主要供应商可以明确,尤其是 MEMS 和液晶方案的上游:
MEMS 方案上游:核心是微纳系统,主要供应商是瑞士的 SELEX(塞莱克斯),这家公司曾经被中国一家工业上市公司收购,后来又被卖出,目前是谷歌 MEMS 交换单元的核心供应商;Lumentum 作为 MEMS 方案的主导厂商,有自己的配套供应商,但具体细分部件(比如 FAU、透镜)供应商比较分散,没有明确的龙头。
液晶方案上游:专家表示,Lumentum 的液晶方案供应商他需要会后核实,但 Coherent(考辛)的液晶部件,主要供应商是藤井(Fujii),藤井也是 Coherent WSS 产品的长期供应商,配套性很强。
另外,FAU、透镜等通用部件,供应商比较分散,没有绝对的龙头,各家厂商都有自己的合作供应商,技术门槛不高,价值量也较低,后续不会成为供应链的瓶颈。
06|英伟达 GPU+OCS 的网络架构有什么优点?未来会用什么 OCS 方案?
首先纠正一个关键误区(专家反复强调,非常重要):CPO 和 OCS 没有直接关系,更不是 “OCS 包含 CPO”,网上很多文章说 “CPO 是 OCS 的一部分”,都是错误的,非常误导人!
具体来说:CPO 是光电转换的结构单元,本质上是替代光模块的,主要用在 scale up/scale out 系统的交换芯片旁边;而 OCS 里面没有光电转换器,不需要 CPO,两者不是替代关系,而是可以配套使用的合作关系 ——OCS 可以和 CPO 配套,也可以和传统光模块配套;CPO 可以和 OCS 配套,也可以和传统电交换机配套,没有绑定关系。
回到英伟达的方案:目前英伟达还没有确定 OCS 的具体技术方案,因为它现在的核心精力在 OCS 控制软件的研发上,硬件方案要等到 2028 年才会最终确定。从目前的情况来看,英伟达大概率会在 MEMS 和液晶方案中选择,压电晶体和硅光波导方案还太不成熟,短期内不会考虑。
至于英伟达 GPU+OCS 架构的优点,核心是“提升系统灵活性”:OCS 的切换速度越快,交换颗粒度就越细(比如毫秒级切换相当于 “火车扳道岔”,切换整列火车;纳秒级切换相当于 “菜鸟驿站”,切换单个包裹),而英伟达的核心需求是提升 GPU 集群的互联效率,OCS 的加入能让算力调度更灵活、更高效,尤其是在大规模算力集群中,这个优势会更明显。另外,英伟达对 OCS 的功耗、成本要求不高,最看重的就是切换速度和系统灵活性。
07|2027 年是 CPO 大规模上量年?scale up/scale out 领域的最新进展如何?
先讲大背景:过去光模块的速率迭代是有规律的,100G、400G、800G、1.6T,每 4 年翻倍,但到了3.2T 时代,这个路径被打断了—— 单通道 400G 的 3.2T 光模块要么做不出来,要么做出来后,交换芯片和光模块之间十几厘米的传输距离无法实现稳定传输。
正是因为这个瓶颈,行业才出现了CPO、NPO、XPO、Micro LED 四个赛道,和传统可插拔光模块争夺 3.2T 时代的市场份额,目前整个行业处于“混沌状态”,没有统一的行业共识,各家厂商的观点都基于自身的技术和利益,差异很大。比如英伟达力推 CPO,谷歌在 OFC 大会上公开批评 CPO,认为可插拔光模块或 NPO 更好,旭创等光模块厂商则在多赛道布局,没有明确的倾向性。
专家花了大半年时间研究这个课题,给出的个人判断很实在:
scale out 领域(交换机层面):3.2T 可插拔光模块大概率会成功,即使失败,XPO 方案也能补位(XPO 是过渡方案,成本高但技术成熟),所以 scale out 领域,传统可插拔光模块依然会是主流,CPO 很难有大的突破 —— 云厂商有选择权,CPO 成本高、灵活性差,不是最优选择。
scale up 领域:分厂商来看,英伟达的 scale up 机架没有空间容纳可插拔光模块,只能用 CPO,而且 CPO 在英伟达机架中的价值量占比很低(即使 CPO 成本翻倍,在整个几千万美元的机架成本中,占比也很小),所以英伟达会全力推广 CPO,CPO 在英伟达的 scale up 方案中会成为主流;而华为的 scale up 方案,大量使用光模块(GPU 和光模块的比例达到 20:1),不需要 CPO,所以华为的 scale up 领域,CPO 没有机会。
总结:2027 年 CPO 会大规模上量,但主要集中在英伟达的 scale up 领域,整体市场规模不会像市场预期的那么大,scale out 领域依然是可插拔光模块的天下。08见附件
09|2026-2027 年,EML、CW 激光器的需求、增量及厂商竞争格局如何?
这部分是上游核心,专家拆解得非常细,尤其是区分了 100G EML 和 200G EML,还有不同功率的 CW 激光器,数据详实,没有模糊表述:
先讲EML 激光器(核心短缺品种):
100G EML:第一梯队是 Lumentum(鲁门特)、三菱,第二梯队是博通、住友,第三梯队是 Coherent(考辛)、索尔思,这 6 家厂商都能大规模量产(月产量上百万个)。2026 年的需求看似很大,但要注意“超量下单”的问题 —— 行业甩鞭效应明显,上游需求被放大,实际真实需求和供应量基本匹配,所谓的 “短缺”,很大程度上是超量下单导致的泡沫。
200G EML:目前只有 Lumentum 和三菱能大规模量产,其他 4 家只能送样,无法量产,核心原因是合格率低。下游厂商(旭创、新易盛、Coherent)如果买不到 200G EML,会转而使用硅光方案,所以 200G EML 的真实需求很难准确预测,取决于量产进度和硅光方案的替代速度。
再讲CW 激光器(老技术,需求稳定):
CW 激光器不是新技术,20 年前就有应用,价值量和利润率都比较低。目前主要厂商是 Lumentum(做得最好)、住友,三菱、博通、索尔思基本不做 CW 激光器。
分功率来看:100 毫瓦、170 毫瓦的 CW 激光器,主要配套 1.6T 光模块,Lumentum 和住友都能量产;400 毫瓦的高功率 CW 激光器,目前只有 Lumentum 一家能量产,其他厂商都只能勉强研发,无法量产。高功率 CW 激光器主要用于 CPO 方案,需求随着 CPO 的上量会逐步增加,但短期内量不会太大。
下游厂商选择:新易盛更倾向于使用 EML 激光器,旭创因为自身硅光技术较强,更倾向于使用 CW 激光器(搭配硅光方案),两者的选择差异,也会影响 EML 和 CW 的需求结构。
10|磷化铟衬底的作用、供需关系及供应格局如何?缺口有多大?
先通俗解释一下衬底的作用:衬底是光芯片产业链的“基础”,相当于 “披萨饼的饼底”,本身没有光功能,但所有光芯片都需要在衬底上做外延片,再加工成光芯片,最终用于光模块。目前光芯片用的衬底,主要是磷化铟衬底。
供应格局:目前全球磷化铟衬底的主要厂商只有两家 ——住友(日本)和 AXT(通美,美国),其中住友的规模更大,通美规模较小,两家基本垄断了全球市场,没有其他有竞争力的厂商。
供需关系:目前磷化铟衬底处于“供不应求”的状态,价格持续上涨,4 寸衬底的价格已经涨到几百美元甚至 1000 美元级别。核心原因有两个:一是 AI 数据中心爆发,光模块需求激增,带动衬底需求(是正常需求的 10-20 倍);二是衬底的核心原材料“铟” 是稀土金属,受中国出口管制影响,供应受限,尤其是日本住友,受影响最大,美国、欧洲厂商相对好一些。
缺口情况:如果按订单量计算,目前两家厂商的产能,距离订单需求还差4-5 倍,交期长达大半年到一年;但如果按真实需求计算,缺口没有这么大,因为行业超量下单现象严重,上游衬底的需求被放大的倍数最大,实际真实需求和产能的缺口,大概在 1-2 倍左右,泡沫成分较多。
专家判断:这种供需不平衡的状态,会持续一段时间,但随着住友、通美的扩产,以及超量下单泡沫的消退,缺口会逐步缩小,不过短期内(2026-2027 年),衬底依然会处于短缺状态,价格维持高位。
11|英伟达 scale up 方案中,CPO 交换机的价格和成本构成是什么?哪些部件价值量高?
专家坦诚:目前无法准确估算 CPO 交换机的成本和价格,核心原因是“量产未落地,样品成本无参考意义”。
具体来说:目前英伟达的 CPO 方案,都是台积电生产的样品,半导体设备的特点是 “没有量产规模,成本会极高”—— 样品成本可能是未来量产成本的几千倍、上万倍,而且英伟达为了生产 CPO 芯片,甚至用到了几纳米的光刻机,设备折旧成本是大头,怎么摊销折旧,目前无法判断,所以成本和价格都无法准确估算。
不过专家拆解了 CPO 的方案差异,以及成本构成的核心逻辑,能帮我们大致判断:
CPO 的主要方案:分为两种,一种是硅光集成方案(英伟达 + 台积电的 MRM 方案、博通 + 台积电的 MZM 方案),另一种是分离元件方案(英伟达 + 天孚通信的方案)。分离元件方案的成本,和光模块的光引擎成本差不多,处于同一数量级,相对可控;硅光集成方案的成本,取决于设备折旧摊销,目前无法估算。
成本构成差异:英伟达的硅光集成方案,需要复杂的 SOPC 封装 + QFP 封装,成本比博通的硅光集成方案高,但优势是密度高,能在同一片芯片上做更多通道,可以大幅摊销成本;博通的方案不需要复杂封装,成本相对较低,但密度不如英伟达。
高价值量部件:核心是硅光集成芯片(如果是硅光方案),或者分离的光元件(如果是分离方案),这两个部件是 CPO 成本的核心,占比最高;其次是封装成本,尤其是英伟达的复杂封装,成本占比也很高。
12|中美上游公司竞争力如何?源杰科技、天孚通信、长芯博创点评?
先明确上游核心短缺环节:目前光互联上游最紧缺的是光芯片(尤其是 EML)、DSP、旋光片,另外还有一个容易被忽略的短缺 —— 工程师,没有足够的工程师,产能无法提升。
中美厂商格局:
光芯片(EML):主要厂商是 Lumentum、三菱、博通、住友、Coherent、索尔思(东山精密),其中只有索尔思算是 “半个中国公司”(芯片厂在台湾),其他都是美国、日本厂商,国内厂商目前还无法大规模量产 EML,竞争力较弱。
DSP、旋光片:DSP 主要厂商是 Marvell、博通(美国);旋光片主要厂商是 Coherent、Guaropt(日本住友和三菱的合资公司)。国内有三家厂商(厦门申、成都菲瑞特、福州福晶科技),但总市场份额不到 10%(约 7-8%),竞争力有限。
重点国内公司点评(专家很熟悉,点评很实在):
源杰科技:创始人是索尔思以前的总工程师,技术路线和索尔思基本一致。目前公司最量大的产品是 25G DFB 芯片,CW 芯片已经能大规模发货,年销售额达几亿元,但 100G、200G EML 目前只能送样,无法大规模量产,预计 2026 年下半年或 2027 年才能实现量产,今明两年的核心增长点是 CW 芯片。
天孚通信:本质是“伪装成光引擎公司的精密元件生产商”,70-80% 的销售额来自光引擎,但光引擎的核心精密元件(精密陶瓷件、塑料件、金属件、光学件)都是自己生产的,核心竞争力在精密制造,利润率很高。核心客户是英伟达,客户基础很好,但缺点是没有集成技术,未来如果行业走向集成方案(比如 CPO 硅光集成),天孚只能做 FAU 等低端部件,增长空间会受限;如果是非集成方案,天孚几乎能做除光芯片外的所有部件,优势明显。
长芯博创:业务分为长芯和博创两部分,长芯业务更好—— 主要做跳线、AOC 等产品,客户是谷歌(北美云厂),客户稳定、利润率高,而且无论未来是 CPO、NPO 还是可插拔光模块,都需要这些产品,没有替代方案,增长性稳定;博创业务相对较弱,主要做低速率铜级光模块,竞争力不强。整体来看,公司增长稳定,适合长期布局。
专家说的都是干货,但是在我看来它最大的股东长飞光纤市场认为是企业最大的优势,恰恰是最大的弱点,国企文化和朝令夕改的策略一定会在未来长期显现(长飞未来一定会在某个节点被民营厂暴击),否则现在出海的应该是三大运营商而不是华为。
。。。。。。。。。。。。。。。。。。。。。
存算一体芯片技术专家交流纪要
01 问:存算一体芯片,到底和传统 GPU、近存计算有啥本质区别?优势真的有那么大吗?
答:这是大家最开始接触存算一体时,最容易混淆的问题,我先把话说透,不绕弯子。首先,三者的核心区别是 “存” 和 “算” 的距离。传统 GPU 是 “中间算、四周存”,中间是计算单元,四周是高带宽显存,这种架构其实是过渡形态,最大的问题就是 “存算分离”,导致算力浪费和成本高企。
给大家一组真实数据:一块 GPU 芯片里,高带宽显存的成本占比高达 30% 甚至更高,相当于英伟达在给三星、海力士、镁光打工;而且在行业推理场景中,GPU 的算力冗余特别严重,你花十几万买一张卡,功耗 1000 多瓦,真正用来干活的算力只有 60% 左右,剩下 40% 全是闲置,既费钱又费电。
再看近存计算,很多人把它和存算一体混为一谈,其实严格来说,近存计算只是 “存和算离得近”,并没有真正集成在同一颗芯片上,不算真正的存算一体。而存算一体的核心,是 “存和算放在同一颗芯片上”,计算时直接调用芯片上的存储,不用来回传输数据,这才是 AI 计算芯片的终极形态。
至于优势,说两个最实在的:一是降本空间大,未来存算一体专用芯片的降价空间至少 50%,功耗也能下降 50% 以上,现在主流的 800 瓦芯片,存算一体能压到 100 瓦以下;二是速度快,以英伟达合作的 Grok 芯片为例,它跑模型推理的速度,是传统 GPU 的 5-10 倍,解决了咱们用 AI 时 “输入长文本、等待时间长” 的痛点。
补充一句:存算一体还有个隐藏优势 —— 不依赖先进制程,不用像英伟达那样,非要台积电 2 纳米、1 点几纳米的制程才能保持领先,对咱们国内供应链来说,这简直是量身定制的优势。
02 问:存算一体的技术路线有哪些?SRAM、MRAM、DRAM 到底谁更有前景?
答:目前存算一体的技术路线,主要看底层存储介质,核心就是三种:SRAM、MRAM、DRAM,还有个潜在的 RRAM,咱们一个个说,优缺点、现状、前景都讲清楚,不玩专业术语堆砌。
首先是 SRAM,这是目前最成熟、已经落地的路线,以英伟达合作的 Grok 为代表。Grok 用的就是 SRAM 作为存储介质,在上面集成计算单元,最大的优势是速度快,推理速度能达到 GPU 的 5-10 倍,能满足对速度有极致要求的用户,比如 C 端用户用 AI 生成长文本、行业客户做高速推理,这部分需求几乎占了推理需求的 50% 左右。
但 SRAM 的短板也特别明显:存储容量太小,目前单颗 SRAM 的存储容量只有几百兆,比高带宽显存小太多。给大家算一笔账:同样跑 70B 参数量的模型推理,Grok 的部署成本比 GPU 高 10-15 倍。而且 Grok 成立于 2017 年,用的是十几纳米的成熟制程,属于上一代产品,英伟达还没完成更新,预计下半年或明年才会推出新版本。
然后是 MRAM,这是我个人最看好的未来路线,也是国内少数企业在布局的方向。它的优势很多:第一,断电后数据永久不丢失,不管停电多久,芯片里的数据都不会丢;第二,寿命极长,只要不刻意破坏,几乎不会损坏,不像硅片、SRAM、DRAM 有明确的寿命限制;第三,抗辐射,能用于卫星、航天器,贴合太空算力的发展趋势;第四,功耗比 SRAM 更低,未来降本空间更大。
不过 MRAM 目前还没落地,最大的瓶颈是存储容量比 SRAM 还小,而且还没用到 7 纳米、6 纳米这种相对先进的制程,预计明年才能有初创企业推出产品,实现行业客户的 POC 小批量验证交付。另外,部署 70B 模型推理的成本,目前和 DRAM 类似,都比较高,需要光互联、先进封装等技术来降低成本。
再看 DRAM,目前来看,这条路线几乎走不通,在存算一体的排序里,它排在第四位,落后于 SRAM、MRAM、RRAM。主要原因是它的物理特性限制,很难实现 “存算一体” 的核心需求,目前还没有企业在这条路线上有实质性突破。
最后是 RRAM,目前还处于科研阶段,排在 MRAM 之后,是英伟达未来可能布局的方向,但短期内看不到落地希望。总结一下:现在看 SRAM 是主流,未来 MRAM 是热点,DRAM 基本被淘汰,RRAM 是潜在补充。
03 问:中美存算一体芯片的发展进度差多少?明年真的能前后脚落地吗?
答:这是很多人关心的问题,毕竟大家都想知道国产芯片能不能跟上节奏,有没有机会反超。根据专家的分享,结论很明确:中美存算一体芯片的研发差距并不大,明年几乎会前后脚落地,时间差不会超过半年。
先看美国:目前美国有 Grok(基于 SRAM)已经落地,虽然还没大规模商用,之前在中东计划部署千卡级集群,但因为成本太高搁置了,被英伟达收购后,融入了 CUDA 生态,解决了软件适配的问题。另外,美国还有两家初创企业在做 MRAM 路线的存算一体芯片,但目前产品还没出来,和国内进度差不多。
再看国内:目前国内基于 SRAM 的存算一体芯片公司很少,还处于萌芽阶段,今年才有一些融资流入初创企业,开始布局;基于 MRAM 的企业只有零星一两家,产品还没落地,预计明年才能实现行业客户的 POC 小批量验证交付。
这里要重点说一下:中美最大的区别不是研发进度,而是技术路径和生态适配。美国的存算一体芯片,比如 Grok,融入了英伟达的 CUDA 生态,通用性更强,适配的是全球主流的大模型;而国内的存算一体芯片,离 CUDA 生态比较远,主要适配国内的主流通用大模型,以及基于这些大模型衍生的行业模型和行业应用,走的是 “国产生态适配” 的路线。
还有一个关键点:存算一体芯片对先进制程的依赖度很低,不需要 5 纳米、6 纳米、7 纳米以上的制程,对国内来说,华虹、中芯国际的成熟制程就完全够用,除了良率和海外有差距,其他方面差别不大,这也缩小了中美之间的差距。
04 问:存算一体芯片商业化的最大瓶颈是什么?为什么今年看不到大规模放量?
答:这个问题很实际,很多投资者、行业从业者都在问,专家也直言不讳,目前存算一体商业化的瓶颈主要有三个,每一个都很关键,也是今年无法大规模放量的核心原因。
第一个瓶颈,也是最大的瓶颈:底层存储材料的特性限制,存储容量上不来。刚才也提到,SRAM 单颗只有几百兆,MRAM 更小,而大模型推理需要存储大量参数,比如 70B 参数量的模型,单颗芯片根本装不下,需要多颗芯片拼接,这就导致部署成本反而比 GPU 还高,Grok 部署 70B 模型的成本是 GPU 的 10-15 倍,就是这个原因。没有成本优势,行业客户自然不会大规模采购,今年只能处于 “试点摸索” 阶段,看不到明显放量。
第二个瓶颈:软件端的工具链适配难度大,工作量巨大。芯片本身的研发有难度,但真正能让芯片跑起来、用起来的关键,是软件工具链的适配。不管是 Grok,还是国内的存算一体芯片,目前都和主流的开发者、行业用户习惯的生态不兼容,需要适配大量的算子和框架,这需要时间、资金和人力的投入,不是短期内能完成的。
第三个瓶颈:芯片之间的互联技术难度高。芯片互联有两种方式,一种是芯片厂商自研,难度极高,像 Grok 这样的初创企业,根本没有能力自研,只能找外部合作伙伴;另一种是找外部合作伙伴,但存算一体芯片的物理架构、器件特性,和传统硅基芯片完全不同,通信协议、IP 接口都不一样,合作伙伴需要做大量的技术调整,才能配合存算一体芯片做片间互联,这也拖慢了商业化的进度。
总结一下:今年存算一体芯片的商业化,主要是 “解决可行性”,比如完成小批量验证、适配部分模型,大规模放量至少要等到明年,甚至后年,等存储容量、软件适配、芯片互联这三个瓶颈得到缓解。
05 问:国产存算一体芯片,每瓦输出 TOKEN 效率能赶上 Grok 吗?
答:这个问题问得很专业,也是很多人关心的 “国产差距” 核心问题。说实话,目前还没有一个明确的对比数据,因为不管是国产存算一体芯片,还是 Grok,都还没有真正商用,没有统一的对比参照物,没法给出具体的数值。
但专家给出了一个明确的趋势,大家可以参考:从性价比和行业应用落地来看,国产存算一体芯片有希望超过美国;但从生态和硬件架构来看,美国目前有一定优势。
先看国产的优势:中国的行业智能体发展,远远超过美国。不管是金融、政府治理、生物医药,还是智慧城市,国内的行业智能体落地速度更快、更成熟。而存算一体芯片的核心应用场景,就是行业智能体的端侧推理,国内在行业部署成本上有天然优势,只要适配好国内的主流大模型和行业模型,性价比大概率能超过 Grok。
再看美国的优势:英伟达体系的生态优势很明显,Grok 融入 CUDA 生态后,软件适配难度降低,开发者上手更快;而且英伟达可以复用自己的 Nvlink、Nvswitch,以及未来的光互联技术,在硬件架构上有一定优势。
但这里要强调一点:硬件优势的差距并不大。国内有华为带头做的超节点架构,基于华为自研的鲲鹏 ARM CPU、计算芯片、存储和网络,形成了全套的超节点网络架构,其他国内芯片厂商可以借鉴。而且在光交换、光互联等前沿技术上,国内比美国落地更快,上海西智已经有实际项目落地,而英伟达还没有实际项目落地。
另外,存算一体芯片对先进制程的依赖度低,国内的成熟制程完全能满足需求,供应链上的差距主要在良率,其他方面差别不大。所以综合来看,虽然目前没法对比具体的 TOKEN 效率,但未来国产存算一体芯片在性价比上,大概率能赶上甚至超过 Grok。
06 问:国内有哪些企业在做存算一体芯片?代工环节有哪些企业能承接?
答:目前国内做存算一体芯片的企业不多,主要以初创企业为主,还有少数大厂布局,代工环节则有明确的成熟玩家,咱们一个个说清楚。
首先是设计环节的初创企业:
前寒武纪 CTO 梁军牵头成立的初创公司,技术路线是存算一体,目前已经获得融资,正在推进研发。
杭州的一家三字名初创企业,获得了兆易创新的投资,专注于存算一体芯片研发,目前还没有产品落地,处于研发阶段。
北大物理系牵头的两家初创企业,也是走存算一体路线,主要聚焦于底层技术研发,目前进展相对缓慢,还没有公开的产品信息。
除了初创企业,国内还有一些大厂在相关领域布局,比如华为,虽然华为的 NPU 本身做不了存算一体,但华为在超节点、光互联等领域的技术,能为存算一体芯片提供支撑;另外,百度的昆仑芯、寒武纪、上海燧原等企业,虽然做的是 ASIC 架构,不能直接做存算一体,但在专用芯片领域的技术积累,也能为存算一体的研发提供借鉴。
然后是代工环节:目前国内的华虹、中芯国际,完全有能力承接存算一体芯片的代工业务。因为存算一体芯片不依赖先进制程,5 纳米、6 纳米、7 纳米的制程就已经是很好的配置,华虹和中芯国际的成熟制程,除了良率和海外有差距,其他方面都能满足需求,不需要依赖海外代工厂,这也是国内存算一体芯片的一个重要优势。
补充一句:国内存算一体芯片的玩家目前虽然少,但今年已经有融资流入,随着技术的成熟和商业化的推进,未来会有更多企业入局,尤其是在 MRAM 路线上,国内有机会实现突破。
07 问:国产存算一体芯片,能基于 NPU、ASIC 架构研发吗?为什么?
答:这个问题很关键,很多人误以为 NPU、ASIC 架构也能做存算一体,其实答案很明确:不能,而且是根本做不到。
核心原因很简单:NPU、ASIC 架构的芯片,本质上还是遵循 GPU 的产品设计路线,中间是计算单元,必须依赖旁边的高带宽显存来存储数据,自身没有存储能力,做不到 “存算一体” 的核心要求 —— 存和算集成在同一颗芯片上。
举例来说:华为的 NPU、百度的昆仑芯、寒武纪的芯片、上海燧原的芯片,都是 ASIC 架构,它们的工作模式是 “计算单元 + 高带宽显存”,读取和存储数据都依赖高带宽显存,和 GPU 的架构逻辑一样,只是在专用场景下的算力效率更高,但始终做不到 “存算一体”。
而存算一体芯片的核心,是在 “能存储数据的介质” 上直接做计算,不管是 SRAM、MRAM 还是 RRAM,都是先有存储介质,再在上面集成计算单元,不需要依赖外部的高带宽显存,这和 NPU、ASIC 架构的逻辑完全不同。
简单来说:NPU、ASIC 架构的芯片,是 “计算依赖存储(外部显存)”;存算一体芯片,是 “存储集成计算”,两者的底层逻辑不一样,所以 NPU、ASIC 架构根本做不了存算一体。国内的存算一体芯片,只能走 SRAM、MRAM 这样的路线,不能基于 NPU、ASIC 架构研发。
08 问:存算一体能成为国产 AI 芯片 “弯道超车” 的赛道吗?
答:这个问题是大家最关心的,专家的观点很客观:存算一体不算 “弯道超车”,但却是国产芯片摆脱英伟达束缚、实现 “差异化竞争” 的最佳赛道,甚至有机会在部分领域超过美国。
首先要明确:英伟达在依赖先进制程的算力芯片(比如用于大模型训练的 GPU)领域,优势依然很大,国内短期内很难赶上。但存算一体芯片的路线,和英伟达的 GPU 路线完全不同,它不依赖先进制程、不依赖高带宽显存,主打低成本、低功耗、高速度,适配的是中小用户的端侧推理需求,这正是国内的优势所在。
国内的核心优势有三个:第一,性价比优势,国内能以更低的成本,满足最大数量用户的模型推理需求,这是英伟达的 GPU 很难做到的,毕竟 GPU 价格高、功耗高,很多中小用户用不起;第二,行业智能体优势,国内的行业智能体落地更快、更成熟,存算一体芯片适配国内的行业模型后,易用性和灵活性会更高,能更好地满足行业用户的需求;第三,硬件架构优势,华为的超节点架构已经走在前面,其他企业可以借鉴,而且在光交换、光互联等前沿技术上,国内比美国落地更快,能为存算一体芯片的互联提供支撑。
当然,我们也要清醒地认识到差距:在生态适配方面,国内离 CUDA 生态还有差距,软件工具链的适配还需要时间;在高端芯片的训练能力上,国内依然不如英伟达。但存算一体的核心需求是端侧推理,不是模型训练,而未来推理芯片的需求,会占到整个芯片需求的 80% 甚至更高,这正是国内的机会。
总结一下:存算一体不能让国产芯片在所有 AI 芯片领域超越英伟达,但能让我们在 “端侧推理” 这个最大的细分赛道上,实现 “差异化领先”,摆脱对英伟达 GPU 的依赖,这其实比 “弯道超车” 更有实际意义。
09 问:英伟达接下来会布局哪些存算一体技术路线?会找更多 “Grok” 合作吗?
答:肯定会,而且这是英伟达的必然选择。专家判断,英伟达收购 Grok,只是它布局存算一体的第一步,接下来一定会找第二个、第三个 “Grok”,补充自己的技术短板,满足不同的需求。
首先,英伟达目前的存算一体布局,主要是 SRAM 路线(通过 Grok),但 SRAM 的成本太高,部署 70B 模型的成本是 GPU 的 10-15 倍,虽然速度快,但很难大规模推广。所以英伟达接下来的核心需求,是找到能降低成本的存算一体技术路线,而MRAM 就是最佳选择。
专家预测,英伟达不排除在接下来的时间里,收购美国另外两家做 MRAM 的初创企业,或者和它们达成深度战略合作,补齐 MRAM 路线的短板。因为 MRAM 的物理特性更优越,断电不丢数据、寿命长、抗辐射,而且未来降本空间更大,能弥补 SRAM 成本高的问题。
其次,英伟达还可能布局 RRAM 路线,作为 MRAM 的补充,但 RRAM 目前还处于科研阶段,短期内不会落地。而 DRAM 路线,英伟达大概率不会布局,因为这条路线的可行性太低,很难实现存算一体的核心需求。
另外,英伟达接下来的产品形态,会朝着 “多芯片封装” 的方向发展。比如它的下一代费曼架构,很可能会把存算芯片、GPU、光电一体封装整合在一起,实现 “训推一体 + 极速推理”,打通算力的全链路。这种模式,也会给国内的芯片企业提供参考,未来国内也可能会把 SRAM、MRAM、RRAM 三种芯片封装在一起,提升算力效率。
简单来说:英伟达的存算一体布局,会以 SRAM 为基础,重点布局 MRAM,补充 RRAM,同时通过多芯片封装,整合算力资源,巩固自己的优势。
10 问:国内 scale up(芯片互联)技术发展到什么水平?和英伟达差距多大?
答:这个问题很专业,也是国产芯片的 “长短板” 很明显的领域。总结下来就是:在前沿技术(光交换、光互联、光电共封)上,国内比美国快;但在成熟的网络方案上,国内比英伟达落后。
先看国内的优势:在光交换、光互联领域,国内的上海西智已经有实际项目落地,而且上海西智即将在香港上市,专注于光交换、光互联,未来还会布局光计算。而英伟达的光交换、光互联技术,目前还没有实际项目落地,还处于研发和测试阶段。另外,在光电共封(CPO)技术上,国内也比英伟达略快一点点,时间差大概在半年左右,这种技术能把光互联、光交换直接封装在计算芯片旁边,大幅提升数据传输速度。
再看国内的短板:在传统的高速网卡互联、私有协议互联方面,国内比英伟达落后。英伟达早早就收购了 IB,拥有了基于私有协议的高速网卡,速度能达到 400G、800G,国内很多智算中心、服务器厂商,在交付千卡、万卡集群时,最快的网络方案还是买英伟达的 IB 整套网络方案。
国内目前的自研高速网卡,主要基于 ROCE 协议,速度有 200G、400G,最快的能做到 800G,但成本太高,没有大规模铺开使用。而且国内芯片厂商自研的私有协议,在传输速度上也比英伟达落后。
不过有一个亮点:国内在架构设计上有创新,比如华为的超节点架构,绕过 CPU,在 GPU 之间实现了全新的通信架构,从软件和通信链路上做了优化,比英伟达的架构更先进,甚至英伟达的费曼架构,都有借鉴华为超节点的影子。
总结一下:国内在芯片互联的前沿技术上领先,但在成熟的网络方案、协议速度上落后,不过通过架构创新,我们正在缩小差距,未来在芯片互联领域,有机会实现突破。
11 问:目前哪些领域对 ASIC 芯片的需求最旺盛?为什么?
答:ASIC 芯片(专用芯片)的需求,其实是从 2024 年下半年才开始爆发的,核心原因是国内行业大模型的落地,尤其是 DeepSeek、千问、MiniMax 这些能真正在行业里落地应用的大模型出现之后,ASIC 芯片才迎来发展机遇。
先给大家讲个行业情况:2024 年上半年,ASIC 芯片的市场表现不佳,华为、寒武纪、上海燧原的 ASIC 芯片,市场销量较低,甚至有用户采购后因无法适配当时的各类模型而闲置,大家更倾向于选择英伟达的 A100、A800 芯片。因为当时的很多模型依赖英伟达的 CUDA 生态,ASIC 芯片难以适配。
而 2024 年下半年,DeepSeek、千问这些国内大模型落地后,情况发生转变。这些大模型能够切实服务于行业场景,比如会议纪要撰写、PPT 制作、行业数据处理等,行业用户的核心需求明确,不需要芯片适配所有模型,只要能适配自身常用的 1-2 个模型,实现算力最优、成本最低即可。
这就为 ASIC 芯片创造了机会,ASIC 芯片无需适配全品类模型,只需针对性适配 1-2 个行业模型,就能满足用户需求,且成本与功耗均低于 GPU,性价比优势突出。从 2024 年下半年到 2025 年上半年,华为、寒武纪、百度昆仑芯的 ASIC 芯片,搭载 DeepSeek、千问模型打造的一体机,市场表现十分亮眼。
目前需求最旺盛的领域,主要是各类需要行业智能体的行业,包括泛政府领域、医疗领域、教育领域、泛金融领域、交通领域、能源领域。
这些领域的共同特点是:不需要通用算力,只需要针对自身行业的模型做推理,对成本和功耗敏感,而 ASIC 芯片正好能满足这些需求。未来,随着行业智能体的爆发,ASIC 芯片的需求还会持续增长,成为专用芯片领域的核心增长点。
12 问:投资角度看,大模型和 ASIC 芯片两个赛道,哪个更有前景?
答:专家的观点很明确:从长期来看,ASIC 芯片赛道比大模型赛道更有前景,简单来说就是 “卖铲子的比挖金子的更赚钱”。
先看大模型赛道:大模型的发展趋势是 “垄断化”,最后只会剩下几家大厂,国内的百度、阿里、华为,国外的 OpenAI、谷歌、英伟达,这些大厂会垄断通用大模型市场,然后基于自己的通用大模型,孵化出垂域的行业智能体。中小模型厂商生存空间有限,要么被大厂收购,要么被淘汰,最终市场格局会高度集中,留给中小投资者的机会不多。
再看 ASIC 芯片赛道:ASIC 芯片是 AI 落地的硬件基础,不管是大模型训练、行业智能体推理,都离不开 ASIC 芯片。而且 ASIC 芯片的需求是 “多元化” 的,不同行业有不同的需求,不需要一家企业垄断整个市场,会有很多聚焦细分领域的专用芯片公司,凭借高性价比构建自身护城河,在行业中立足。
还有一个很实际的点:从用户感知来看,硬件产品更受青睐。用户购买 ASIC 芯片,获得的是实体产品,而大模型更多是服务类产品,用户感知相对较弱。而且随着 AI 的落地应用,芯片的销量会大幅增长,营收和利润的确定性更高,而大模型的盈利模式仍在探索中,不确定性相对较大。
补充一句:国内市场规模庞大,未来中国的模型、算力、智能体均有出海与国际竞争的潜力,这会为国内 ASIC 芯片企业带来更多发展机会。相比之下,大模型出海受地域、政策影响更大,而 ASIC 芯片作为硬件产品,出海门槛相对更低,发展前景更为广阔。
聊了这么多,其实核心就一句话:AI 算力的未来,是 “专用化”,而存算一体和 ASIC 芯片,就是专用化赛道的核心。
国内的优势是:不依赖先进制程、行业智能体落地快、性价比高,而且在光互联等前沿技术上已经领先;短板是:软件生态适配不足、成熟网络方案落后、初创企业偏少。但随着融资的流入、技术的成熟、商业化的推进,这些短板都会逐步补齐。
未来 3-5 年,推理芯片会占到整个芯片需求的 80% 以上,存算一体和 ASIC 芯片,会成为这个赛道的主角。对投资者来说,ASIC 芯片赛道的机会更多;对行业来说,存算一体会让算力普惠,让更多中小用户用得起 AI 算力;对国产芯片来说,这是摆脱英伟达束缚、实现差异化领先的最佳机会。
所以最后综上所述:
端侧推理芯片ASIC(群雄逐鹿)>Q布(但是Q布的标的异常清晰)>存储(目前看也是超市错觉)>npo,xpo,ocs(后面只有懂的人能赚钱)>半导体设备(是人都能赚钱)
无论是选股还是养狗,我们都要有专业精神![]()
![]()





本话题在雪球有141条讨论,点击查看。
雪球是一个投资者的社交网络,聪明的投资者都在这里。
点击下载雪球手机客户端 http://xueqiu.com/xz]]>
#半导体行业观察上限看端侧下限看Q布由光入布好