巴菲特和刷马桶的,在AI眼里没啥区别
本文来自微信公众号: 非凡油条 ,作者:豆腐乳儿
“我今年95岁,除了时间和樱桃可乐一无所有。我想知道,这样我也好告诉其他股东,为什么他们应该长期持有伯克希尔的股票?”
一个熟悉的声音出现在伯克希尔股东大会上,在座众人认出是股神巴菲特的声音。
巴菲特已经退休了,怎么又出现在最近的伯克希尔股东大会上了呢?
原来出席大会的声音和形象,是用AI生成的,完全不需要他本人参与,只需要收集他过往的媒体内容就能生成。
巴菲特在股市里做到了顶尖,所以他的经验被AI炼化也有人愿意听。
可大多数人都是普通人,会有什么值得被AI炼化、学习的东西吗?
还真有,不需要你做什么高难度的事情,你的日常动作,AI都会拼命吞噬,疯狂学习。
炼化动作,遍布全球
同样是在美国,外卖平台DoorDash的配送员接到一项新任务。
他们得佩戴随身摄像机,拍摄自己清洗至少五个碗碟的过程,每个洗干净的碗碟要在画面中停留几秒钟。
他们还会被分派其他类似的家务劳动,随后根据系统判定的努力和复杂程度得到报酬。他们的动作会被当做人类运动数据拿去训练AI。
聪明的你肯定想得到,类似的劳动力密集型平台有收集人类动作数据的优势,这些平台除了外卖还有网约车。
Uber就在去年年底跟进,让司机上传照片帮助训练AI模型。
类似的事情也发生在众多人力成本更低的发展中国家。
一个尼日利亚医学生,在每天从医院回家后,把iPhone绑在额头上,像梦游一样举起双手,给床铺上床单。
他动作缓慢而小心,确保双手始终留在镜头画面内。
他这么做是因为接了Micro1公司的兼职,录制真实人类的家务动作,出售给机器人公司训练AI。
Micro1这家公司大家可能不打熟悉,这是家位于美国加州的创业公司,在全球50多个国家雇用了数千名兼职,让他们把iPhone固定在头上,录下自己叠衣服、洗碗和做饭的过程。
无论是DoorDash、Uber还是Micro1,它们都充当起了人类动作数据的二道贩子。
这生意有多赚钱?Micro1估计,机器人公司现在每年花费超过1亿美元向该公司和类似公司购买真实世界数据。
具身智能,数据饥渴
机器人公司能出这么多钱买真实人类数据,反映了这一行业的突飞猛进。
2025年,人形机器人领域的投资超过60亿美元。
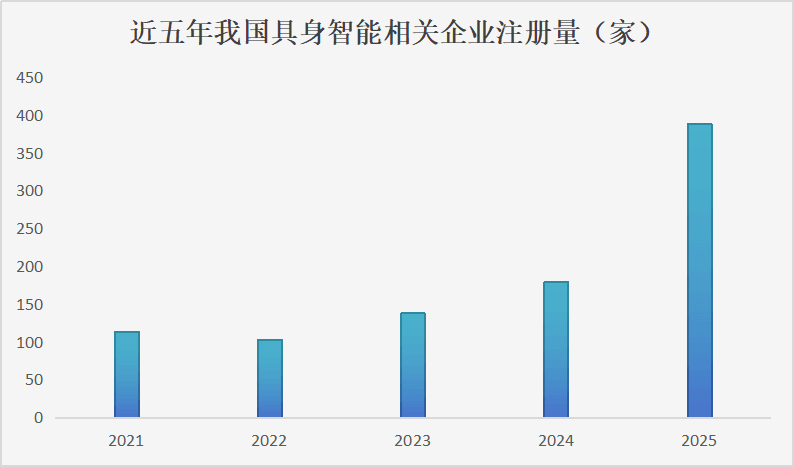
光是2005年国内的具身智能相关企业注册量,就比2024年翻了一番。

☉数据来源:企查查
过去制约机器人性能的硬件,比如行星滚柱丝杠、力矩电机、力矩传感器、谐波减速器等,已经有了长足的进步。
反而是机器人的智能领域,有些跟不上了。
机器人智能训练需要大量数据,而且和大语言模型不同的是,具身智能模型的数据不能蒸馏,只能老老实实自己收集。
目前行业高质量数据总共也就50万个小时左右,远远不够训练具身智能的。
训练大语言模型相对容易一些,毕竟网上就有很多语料,即使这样也招募了很多数据标注员帮助大模型理解数据,训练智能。
但很快人们就发现,AI帮人类写报告做PPT,比帮人类打扫房间容易多了。
人类的动作比语言复杂多了,毕竟模仿人类动作,机器人要理解三维空间、人类感知和物理规律,比起语言文字有更高难度。
这就需要更多数据。
人形机器人正在如饥似渴地吞吃人类动作数据,学习人类是怎么做事的。
所以有人就把动作数据收集做成了生意,人类的身体被重新定义为”活体传感器”。
每一次叠衣服的手部轨迹、每一次抓取碗碟的指节弯曲、每一次跨越房间的步伐,都被转化为训练数据,灌入所谓的大行为模型(Large Behavior Model)。
正如大语言模型通过海量文本学会生成文字,人形机器人正试图通过在大量人类动作数据上训练,学会与世界互动。
动作数据收集,还只是开始
这股数据饥渴并非硅谷独有。中国具身智能数据采集训练场正掀起建设热潮,其速度和规模非常惊人。
智元机器人在上海、成都等地布局数据采集中心。
帕西尼感知科技宣布新建4座超级数据采集工厂。
京东宣称要建成全球规模最大、场景最全的具身智能数据采集中心。
有公司在小区租下几十套房子,专门收集家居场景数据。
还有从事动画动捕业务的公司,让动捕演员在穿戴好设备后跳完一段舞蹈或打一套武术,收集运动控制训练数据喂给机器人。
这些收集到的数据里,最贵的是真机遥操作数据。这是用真实的机器人遥控做出来的数据,质量高,但采集成本高、效率低,市场价格在每小时500至1000元之间。
上面提到的真人收集数据价格在真机数据的三分之一到二分之一左右,高动态数据,比如打球、跑酷等动作则贵得多,价格可达10元/秒。
从目前的价位来看,虽然高难度动作给钱多,但日常动作仍然有其价值——毕竟目前的机器人还没学会打扫房间晾衣服等简单家务。
这就像当年语言大模型还不够智能的时候,为了训练ChatGPT,OpenAI雇佣了时薪不到2美元的外包肯尼亚劳工,进行较为简单的数据标注。
现在给机器人收集日常家务动作,就和当初外包肯尼亚人做数据标注类似,难度还不算大。
但语言大模型发展到今天,已经足够智能,要求的数据标注门槛高多了,现在国内大模型招数据标注员都要985硕士起步,最好是行业专家了。
也许过不了几年,具身智能的数据饥渴症就会被海量数据解决,到时候它们只会需要高难度动作,现在收集动作数据的人也会失去这类兼职。

台上“AI巴菲特”,台下“真巴菲特”https://mp.weixin.qq.com/s/LssD9Fwb095glRGLHG_AGQ
具身智能迎万亿级大风口!企查查:具身智能相关企业超2800家https://mp.weixin.qq.com/s/bXR3UYVJZ_aGvRlRBzRSfA
What’s next for generative AI:Household chores and more|MIT Sloan https://mitsloan.mit.edu/ideas-made-to-matter/whats-next-generative-ai-household-chores-and-more#:~:text=In%20a%20recent%20study%20by%20researchers%20from%20the,will%20be%20automated%20within%20the%20next%2010%20years.
DoorDash launches a new’Tasks’app that pays couriers to submit videos to train AI|TechCrunch https://techcrunch.com/2026/03/19/doordash-launches-a-new-tasks-app-that-pays-couriers-to-submit-videos-to-train-ai/
跨界资本加速涌入,具身智能数据采集成风口https://www.yicai.com/news/103163594.html
脑袋绑iPhone录家务视频,时薪15美元,数千零工撑起人形机器人训练大业https://mp.weixin.qq.com/s/ppMG4z1ZWTqn5F4Sa0F3rA
#巴菲特和刷马桶的在AI眼里没啥区别