迅策涨了4倍,中科闻歌也来了,同样的"中国Palantir"故事,这次能讲圆吗?
本文来自微信公众号: 硅基观察Pro ,作者:硅基君,原文标题:《迅策涨了4倍,中科闻歌也来了!同样的”中国Palantir”故事,这次能讲圆吗?》
“中国版Palantir”这个概念,到底有多值钱?
看看港股的的迅策就知道了。
从硅基君发完《半个月暴涨100%!港股最猛的AI公司,讲了一个“中国Palantir”故事》之后,迅策的股价在不到一个月的时间里又翻了一倍多,从140港元一路涨到320多港元。
现在,迅策的市值已经超过1000亿港元。要知道,去年它的收入也不过12.8亿元,市销率接近80倍。
既然这个故事这么性感,自然也有别人盯上了。这不,4月12日,中科院系AI公司北京中科闻歌正式披露了招股书,冲刺“大模型决策第一股”。
从数据看,中科闻歌好像也有点说法。按收入计算,中科闻歌在2024年中国企业级大模型驱动的决策智能服务提供商中排名第一,市场份额为11.4%。过去三年,公司收入更是从2.50亿、3.18亿一路涨到4.05亿。
那么,中科闻歌到底和Palantir有多像?今天我们就来说说这家公司。
/01/
DIOS平台,”本体论”的中国翻版
先来说说,中科闻歌到底在干嘛?
如果你去翻它的招股书,里面充斥着各种高大上的名词。但用人话说,它干的事情和Palantir一模一样——把一堆乱七八糟的数据,变成老板可以直接拍板的决策结果。
支撑这个野心的,是它的核心产品:自研决策智能操作系统”DIOS平台”。
千万别把DIOS当成那种随便套个壳的聊天机器人,这是一套极其复杂的企业级AI系统。
从架构上看,DIOS平台分为三层,堪称对Palantir像素级的复刻:
底层X-Data对应Palantir的Data,负责把企业里乱七八糟的数据洗成AI能吃得下的”数据资产”;
中间层雅意大模型对应Palantir的Logic,充当大脑负责理解和推理;
上层DI-Brain对应Palantir的Action,面向具体业务完成多方案推演,直接执行决策。数据、逻辑、行动。
这套三段式打法,简直就是Palantir”本体论”的中国版翻版。
在这三层里,最苦、最累,但也最核心的,其实是最底层的X-Data。
过去,很多人对企业数字化有个误解,以为只要把数据存下来,上个AI就能自动生钱。
别做梦了。
大多数企业的现状是:数据多得像座垃圾山,但根本用不了。财务的数据在ERP里,销售的数据在CRM里,客户的数据在Excel表里。格式不统一,口径打架,互相之间连个关系都扯不清。
而X-Data要干的脏活,就是冲进这座”数据垃圾堆”,把那些零散的字段重新组织起来,变成”可以被理解和计算的业务对象”。
把不同系统里的张三、李四统一映射成”客户”,把各种奇葩的编号统一成”订单”,然后明确告诉系统:这个客户,买了那个订单。
这就是Palantir吹了十几年的”数据本体论”——用一套结构化的模型,把现实世界里的人、事、物,在虚拟世界里重新建立一套”存在”。
相当于给企业发明了一套统一的”世界语”,系统一旦搞清楚了什么是客户、什么是产品,不同来源的杂乱数据,瞬间就变成了一张有逻辑、有结构的”蜘蛛网”。
为了织好这张网,X-Data的本体体系被设计成了三层:
最底层的基础本体只认”人、地点、时间”这种大白话;
中间的行业扩展开始懂医疗的”保险类型”、能源的”能耗指标”;
最上层的客户定制,连你公司内部最奇葩的合同编码,都能给你安排得明明白白。
经过这套”数据哲学”的洗礼,原本的垃圾数据,就变成了可以直接喂给大模型的AI-Ready数据集。
如果说X-Data解决的是”数据能不能吃”的问题,那么中间层的雅意大模型,解决的就是”AI能不能消化”的问题。
它更像是企业里的”分析引擎”,不仅能看懂长文本和图表,还能在这些复杂信息之间建立隐秘的联系,进行推理判断,而不是简单地总结归纳。
但光会分析还不够,老板要的是结果。这时候,最上层的DI-Brain就出场了。它把大模型的推理能力,直接转化成业务场景里的决策工具。不用写代码,不懂技术的业务员也能用它来推演方案、执行决策。
如果只看招股书里的业务逻辑,它确实与Palantir有不少相似之处。
但问题在于,现实世界远不止这么简单,PPT画得再丰满,往往也掩盖不了商业世界的骨感。
这11.4%的市占率背后,中科闻歌到底交出了一份怎样的商业化成绩单?我们接着往下说。
/02/
Palantir做“深”,中科闻歌做“多”
既然要对标Palantir,我们不妨把两家公司放在同一张桌子上比一比。
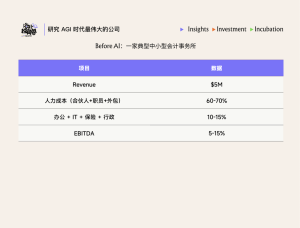
从商业模式看,中科闻歌与Palantir同样都是重交付。2025年,公司72.7%的收入都来自本地化部署。
不过由于项目执行涉及到GPU、服务器、网络设备及存储系统等硬件的采购,公司的毛利率远低于Palantir。2025年,公司毛利率为51.2%,而Palantir长期在80%左右。
再加上相对较高的费用支出,使得公司过去三年的经调整后亏损分别为1.86亿元、1.15亿元和1.01亿元。
但在亏损背后,是中科闻歌与Palantir业务逻辑的差异。
Palantir的核心策略是,瞄准了金字塔尖的大客户,把每个客户做深、做透。这一战略选择的成果体现在收入上,就是客户数量少、客单价极高,且头部大客户至今仍贡献绝大部分营收。
从数据上看,2025年,Palantir的前20大客户,年均贡献是多少?9390万美元,折合人民币接近6.4亿元!
反观中科闻歌呢?过去三年,它的客单价分别是:95.3万、92.9万和100.03万。
从增长逻辑看,中科闻歌更像是靠客户数量扩张驱动,而非客单价提升。
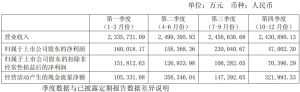
2023-2025年,中科闻歌收入分别为2.50亿元、3.18亿元和4.05亿元,增长了62%。
同期,公司客户数量从262个增长到404个,增长了54.2%。也就是说,绝大部分收入增长都是通过客户数量增长带动的。
而客户数量的增长,主要是通过更多场景的覆盖完成的。
从收入结构来看,中科闻歌的收入具体落在公共服务、商企及传媒与通信三大领域。
2023年,公共服务(G端)是绝对的大头,占比高达50.7%。靠着政府智能问答系统、产业链分析这些项目,日子过得还算滋润。
但到了2025年,公共服务的占比下跌到了36.5%。
去哪找增量?商业企业(B端),商企业务的占比,从2023年的14.5%,一路增长到2025年的31.9%。
根据公司招股书披露,未来公司还将进军教育、能源和医疗行业,来支撑公司未来的收入增长。
但不断拉新背后,掩盖不了一个极其致命的漏洞——客户留存率。
2025年,中科闻歌的客户留存率是多少?55.4%。什么概念?辛辛苦苦谈下来的客户,第二年几乎跑了一半!
要知道,中科闻歌平均获取一个客户的成本高达20万元。花20万拉来一个客户,赚个100万的客单价,结果第二年人就没影了。
所幸的是,另一项指标——净收入留存率,却在持续提升。
所谓的净收入留存率,就是去年已经在你这付费的客户,今年又花了多少钱。
过去三年,公司的净收入留存率分别为66.1%、89.8%和139.5%。到了2025年,甚至略高于Palantir。
换句话说,虽然有一半客户流失了,但留下来的那一部分客户,反而在持续加大投入。
这背后通常意味着两种可能:
一是,公司在核心客户中具备一定价值,能够不断扩展使用场景;
二是,业务结构在向更高价值客户集中;
不过考虑到2023、2024年的净收入留存率仍处于较低水平,2025年的高增值表现,是否具备持续性,还有待进一步观察。
/03/
总结
其实,中科闻歌面临的,并不只是它一家公司的问题,而是所有试图成为“中国Palantir”的公司,共同要面对的约束。
问题首先出在商业环境本身。
国内企业在数字化投入上,更强调短期ROI、快速验收和成本控制。这直接导致,大量项目被压缩为定制开发和驻场服务。
结果是,大家都在做“系统”,却很难沉淀出真正可复用的“操作层”。
更深层次的问题,在企业内部。
国内大型组织往往结构复杂,部门边界清晰、系统彼此割裂、权责分散。这使得外部厂商很难推动跨系统、跨部门的深层改造。
于是,大多数项目只能停留在局部场景的效率优化,而很难触达真正的决策层。
一旦缺少这种深度绑定,AI数据公司就很难往上走,只能停留在“轻集成”层面。
但轻集成的另一面,是商业模式的天花板。
在国内,既能承受高客单价、又愿意长期依赖外部厂商的客户,本来就不多。更现实的情况是,一旦企业意识到数据和智能系统的重要性,往往会选择把能力内化,成立数科公司,自建团队。
这就形成了一个结构性的结果:
中国并不缺少“类似Palantir的产品形态”,但很难长出一家真正意义上的Palantir。
#迅策涨了4倍中科闻歌也来了同样的quot中国Palantirquot故事这次能讲圆吗