
不止于HR值:生存曲线外推的理论框架、标准参数模型与部分实战(一)

<
生存函数S(t)给出了一个人存活时间长于某个指定时间t的概率:也就是说,S(t)给出了随机变量T超过指定时间t的概率( 亦即S(t)=P(T>t) )。
生存函数对于生存分析来说是基础性的,因为获得不同t值下的生存概率,可以从生存数据中提供至关重要的总结性信息。
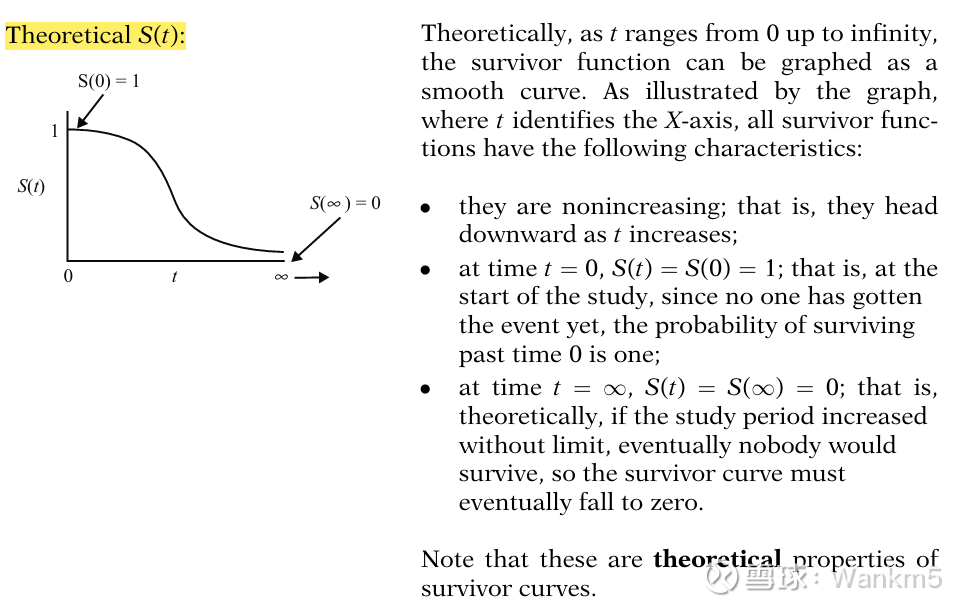
理论上,随着t从0延伸到无穷大,生存函数可以绘制成一条平滑的曲线。如图所示,其中 t标识X轴,所有生存函数都具有以下特征:
它们是非递增的;也就是说,随着t的增加,它们呈下降趋势;
在时间t = 0时,S(t) = S(0) = 1;也就是说,在研究开始时,由于还没有人发生目标事件,存活过时间0的概率为1;
在时间 t = ∞ 时,S(t) = S(∞) = 0;也就是说,理论上,如果研究周期无限制地增加,最终将没有人能够存活,因此生存曲线最终必定会降至零。
请注意,这些是生存曲线的理论性质。

在实践中,当使用实际数据时,我们通常得到的图形是如图所示的阶跃函数,而不是平滑的曲线。此外,由于研究周期的长度永远不可能无限长,而且可能存在导致失败(事件发生)的竞争风险,因此参与研究的人可能并非所有人都发生了该事件。因此,估计的生存函数(在图中用 S 上方加一个脱字符表示,即 S^)在研究结束时可能不会完全降至零。
风险函数,记为h(t),由以下公式给出:h(t)等于一个关于生存的概率表达式除以Δ后,当Δ趋近于零时的极限,其中Δ表示一个很小的时间间隔。这个数学公式很难用实际术语来解释。

在深入探讨公式的具体细节之前,我们先给出一个概念性的解释。风险函数 h(t) 给出了在个体已经存活到时间 t 的前提下,单位时间内发生该事件的瞬时可能性。
请注意,生存函数关注的是不失败,而风险函数与之相反,它关注的是失败,也就是事件的发生。因此,在某种意义上,可以认为风险函数提供了与生存函数所提供信息相对立的另一面。

为了让你更好地理解“瞬时可能性”是什么意思,可以思考一下速度的概念。例如,如果你正在开车,看到速度表显示为 60 mph(英里/小时),这个读数意味着什么?它的意思是,如果在接下来的一个小时里,你继续以这种状态驾驶,速度表精准地保持在 60,那么你将行驶 60 英里。这个读数给出了在你查看速度表的那一刻,你在接下来的一个小时内将行驶多少英里的可能性。然而,由于在接下来的一个小时内你可能会减速、加速甚至停车,所以 60 mph 的速度表读数并不能告诉你下一个小时你真正会行驶的英里数。速度表只告诉你在给定时刻你的速度有多快;也就是说,该仪器给出的是你的瞬时可能性或瞬时速度。
与速度的概念相似,风险函数 h(t) 给出了在存活到时间 t 的条件下,在时间 t 发生某个事件(如死亡或患上某种感兴趣的疾病)的瞬时可能性。其中“条件”这部分,即已经存活到时间 t,就类似于在上述速度的例子中,我们需要认识到:某一时间点的速度表读数,本质上已经假定了在读取数据时,你已经行驶了一段距离(即已经存活了这么长时间)。

用数学术语来说,风险函数公式中“给定”的部分,存在于极限符号右侧分子上的概率表达式中。这个表达式是一个条件概率,因为它的形式是“在给定 B 的情况下 A 的概率(P of A, given B)”,其中 P 表示概率,而分隔 A 和 B 的长竖线表示“给定”。在风险公式中,条件概率给出了一个人的生存时间 T 将落在 t 和 t + Δt 之间的时间间隔内的概率,前提是(给定)该生存时间大于或等于 t。因为这里的“给定”特征,风险函数有时也被称为条件失败率(conditional failure rate)。
我们现在来解释为什么风险是一个率(rate)而不是一个概率。请注意,在风险函数公式中,极限符号右侧的表达式给出了两个量的比值。分子是我们刚刚讨论过的条件概率。分母是 Δt,表示一个很小的时间间隔。通过这种除法,我们得到了一个单位时间内的概率,这就使得它不再是一个概率,而是一个率。需要特别指出的是,这个比值的取值范围不像概率那样在 0 到 1 之间,而是在 0 到无穷大之间,并且它取决于测量时间所使用的单位是天、周、月还是年等。
例如,如果概率(这里记为 P)是 1/3,时间间隔是半天(1/2 天),那么概率除以时间间隔就是 1/3 除以 1/2,等于每天 0.67。再举个例子,假设对于同样 1/3 的概率,时间间隔以周来计算,那么半天就等于 1/14 周。此时,概率除以时间间隔就变成了 1/3 除以 1/14,等于 14/3,即每周 4.67。举这些例子的重点仅仅在于说明,极限符号右侧 P 除以 Δt 的表达式并没有给出一个概率。它所得到的值会根据所使用的时间单位而变化,甚至可能会得出一个大于 1 的数字。

当我们取右侧表达式在时间间隔趋近于零时的极限时,我们本质上得到的是在时间 t 时每单位时间发生失败(事件发生)的瞬时概率的表达式。换一种说法就是,条件失败率或风险函数 h(t) 给出了在存活到时间 t 的条件下,在时间 t 每单位时间发生失败的瞬时可能性(potential)。
与生存函数一样,当 t 取不同的值时,风险函数 h(t) 也可以被绘制成图形。左侧的图例说明了三种不同的风险。与生存函数不同,h(t) 的图形不需要从 1 开始并下降到 0,而是可以从任何点开始,并随着时间的推移向任何方向起伏。具体而言,对于一个指定的 t 值,风险函数 h(t) 具有以下特征:
①它是始终非负的,也就是说,等于或大于零;
②它没有上限。
这两个特征源于 h(t) 公式中的比值表达式,因为分子中的概率和分母中的 Δt 都是非负的,并且 Δt 的取值范围可以在 0 到 ∞ 之间。

现在我们展示一些不同类型的风险函数的图形。给出的第一张图显示了一项针对健康人群研究的恒定风险(constant hazard)。在这张图中,无论指定什么 t 值,h(t) 都等于同一个值——在这个例子中是 λ。请注意,对于在整个研究期间持续保持健康的人来说,他/她在该期间任何时候生病的瞬时可能性在整个随访期间保持不变。当风险函数是恒定的时候,我们称该生存模型为指数的(exponential)。这个术语来源于生存函数和风险函数之间的数学关系。我们稍后将再次讨论这种关系。
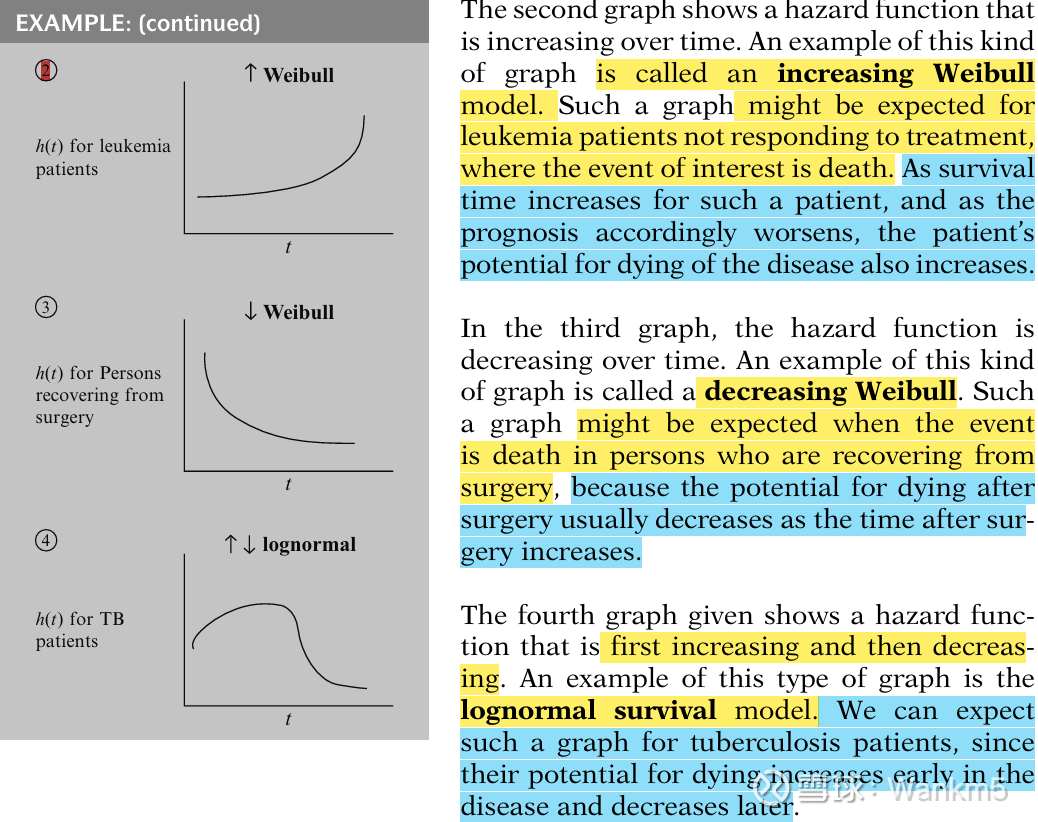
第二张图显示了一个随时间递增的风险函数。这类图形的一个例子被称为递增的威布尔(increasing Weibull)模型。对于对治疗无反应的白血病患者(在此类情况中,感兴趣的事件是死亡),我们可能会预期出现这种图形。随着这类患者生存时间的增加,以及预后的相应恶化,该患者死于这种疾病的可能性也随之增加。
在第三张图中,风险函数随时间递减。这类图形的一个例子被称为递减的威布尔(decreasing Weibull)模型。当目标事件是术后恢复期患者的死亡时,我们可能会预期出现这种图形,因为手术后死亡的可能性通常会随着术后时间的推移而降低。
给出的第四张图显示了一个先升后降的风险函数。这类图形的一个例子是对数正态生存(lognormal survival)模型。我们可以预期结核病患者会出现这种图形,因为他们死亡的可能性在疾病早期增加,而在后期降低。
为了方便大家的记忆,我把指数模型(exponential model)称为“匀速掉血”模式,它就像老派化疗,患者在每个月面临的死亡风险都是一样的,每个月都有固定的概率被死神带走。所以风险曲线是一条斜率不变的直线。
而威布尔分布(Weibull)则可以被称为“毒性累积/加速掉血”模式,这就像某些毒性极大的ADC或早期靶向药,随着用药周期的增加,毒副作用(例如某些严重的靶向外毒性或ILD)在体内不断叠加,患者的耐受度逐渐逼近极限,导致其面临的风险越来越高(此处特指递增的Weibull模型)。
至于对数正态生存模型(Lognormal survival model),我们可以称之为“渡劫/先爆后稳”模式。这就像是某些高风险但有望带来长效获益的疗法(比如CAR-T或某些强效双抗),患者在治疗初期必须直面剧烈的急性毒性(如严重的CRS细胞因子风暴),死亡风险在短期内迅速攀升至顶峰;但只要患者“扛”过了这段最危险的“渡劫期”,随着身体逐渐适应或肿瘤负荷被有效压制,后续的风险就会逐渐回落。

在我们考虑的 S(t) 和 h(t) 这两个函数中,生存函数在进行生存数据分析时显得更直观、更自然,原因很简单:S(t) 直接描述了研究队列的生存体验。
然而,出于以下原因,风险函数也同样具有重要意义:
①它衡量的是瞬时可能性,而生存曲线是随时间变化的累积指标;
②它可用于识别特定模型的形式,例如识别出适合当前数据的指数曲线、威布尔曲线或对数正态曲线;
③它是进行生存数据数学建模的载体(vehicle);也就是说,生存模型通常是基于风险函数来构建表达的。

无论偏好 S(t) 还是 h(t) 中的哪一个函数,这两者之间都存在着明确定义的联系。事实上,如果已知 S(t) 的形式,就可以推导出相应的 h(t),反之亦然。例如,如果风险函数是恒定的,即对于某个特定值 λ,有 h(t) = λ,那么可以证明相应的生存函数由以下公式给出:S(t) 等于 e 的负 λ 乘以 t 次方(注:即 S(t) = e^(-λt))。
更一般地说,S(t) 和 h(t) 之间的关系可以等价地表示为此处展示的两个微积分公式之一。
这些公式中的第一个描述了如何用包含风险函数的积分来表达生存函数 S(t)。该公式表明,S(t) 等于风险函数在积分下限 0 到上限 t 之间的负积分的指数形式。
第二个公式描述了如何用包含生存函数的导数来表达风险函数 h(t)。该公式表明,h(t) 等于 S(t) 对 t 的导数的负值,再除以 S(t)。
在任何实际的数据分析中,计算机程序都可以完成从 S(t) 到 h(t) 的数值转换(反之亦然),而不需要用户亲自去使用这两个公式中的任何一个。这里的重点仅仅在于:如果你知道了 S(t) 或 h(t) 中的任何一个,你就可以直接得到另一个。
接下来,我们将目光转到NICE(英国国家卫生与临床优化研究所)的技术评估报告TSD 14,以进一步理解参数分布模型及其具体的应用。
二、理解生存分析建模方法及参数分布模型

生存分析是指测量两个事件之间的时间——在临床试验中,这通常是从随机分组到疾病进展(通常称为无进展生存期,特别是在癌症疾病领域)或死亡(总生存期)的时间。生存数据不同于其他类型的连续数据,因为通常无法在所有受试者中观察到感兴趣的终点——患者可能会失访,或者在研究随访结束时事件尚未发生。这些患者的数据被删失,但仍然有用,因为它们为每位删失患者实际未观察到的生存时间提供了一个下界。生存分析技术允许使用这些数据而不是将其排除;然而,可以使用一系列不同的生存分布和模型。模型的选择可能会导致不同的结果。这里将讨论这些替代方法。需要注意的是,这里讨论的标准生存分析方法仅在删失是无信息的(即任何删失都是随机的)情况下才适用。

除非临床试验的生存数据是完整的,或者非常接近完整——也就是说,大多数患者在随访结束时已经经历了该事件——否则就需要进行外推,以便生存数据能有效地纳入卫生经济学模型中。一般来说,这是通过使用拟合经验性事件发生时间数据的参数模型来实现的。虽然存在替代方案,但当存在删失时,这些方案通常不适用。例如,限制平均分析(restricted means analysis)通常仅涉及基于可用数据估计平均值(尽管它也可能意味着仅外推到特定时间点)。同样,稍后将讨论的Cox比例风险回归模型也仅基于观察到的数据进行推断。然而,此类方法只有在数据几乎完全完整时才可能是合理的,否则它们将无法产生对平均生存期的准确估计,也无法反映预期生存时间的完整分布,因为省略更极端的、需要外推的数据点会影响这些结果。因此,在大多数情况下,参数模型可能是将生存数据纳入卫生经济学模型的首选方法。在这种情况下,问题就变成了:在只有部分信息——甚至完全缺乏信息——的情况下,如何最好地对概率分布的尾部进行推断。例如,在生命周期数据不成熟且未删失的观察值仅存在于一小部分患者的常见情况下,必须格外小心。
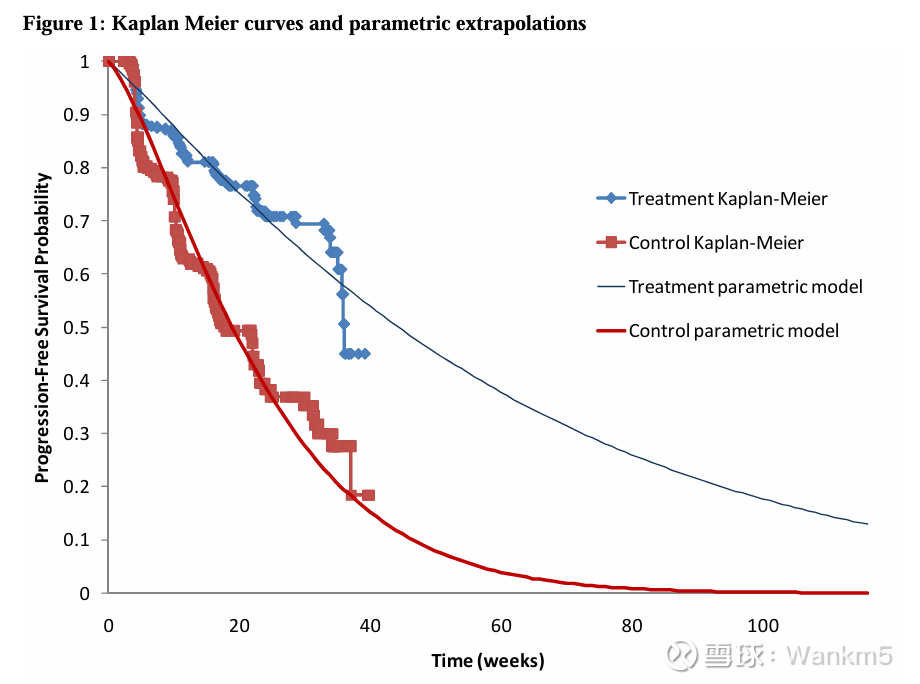

图1说明了如何使用参数模型对外推生存数据。该图显示了直接取自临床试验生存数据的、对照组和治疗组在一段时间内感兴趣事件(在本例中为无进展生存期)的生存函数的非参数Kaplan Meier估计。在这个例子中,随访在大约40周后结束,此时在治疗组中,截至此时未被删失的患者中,大约有45%尚未经历感兴趣的事件。对照组的这一对应数字约为20%。由于该图表绘制了试验人群随时间推移的生存情况,因此试验人群的平均生存期等于曲线下的面积。然而,由于一部分患者在40周随访期结束时仍然存活,因此只能直接估计受限于该时间点的平均值。如上所述,可以使用参数模型来避免依赖于受限平均值的估计。图1展示了生存数据的参数外推(在本例中使用了威布尔/Weibull模型),这证明了如何对外推生存数据进行外推,从而获得每个治疗组平均生存期的无限制估计值——对模型进行拟合,并可以估计曲线下的总面积。在这些情况下,基本情况分析(base case analysis)应使用拟合概率分布的外推法,尽管同时呈现仅基于观察数据的结果,也可能为外推期在决定平均值时的重要性提供有用的信息。


图1还展示了Kaplan Meier曲线的“阶梯状”特征,这是因为随访仅在预先设定的时间间隔内进行——在本例中为每6周一次。这意味着仅在6周的间隔时才观察到事件的发生。在某些情况下,这可能会在生存分析结果中产生偏差——特别是当随访间隔相对较长时。在这些情况下,应考虑使用区间删失(interval censoring)方法。Collett(2003)⁴ 探讨了可能的方法,并且这些方法在标准统计软件库中可用。Panageas 等人(2007)⁵ 讨论了相关问题。应当就所采取的方法在经济模型中的应用证明其合理性。
有许多参数模型可供选择,每种模型都有其自身的特点,这使得它们适用于不同的数据集。指数(Exponential)、威布尔(Weibull)、贡佩尔茨(Gompertz)、对数逻辑(log-logistic)、对数正态(log normal)和广义伽马(Generalised Gamma)参数模型都应予以考虑。下面将介绍这些模型,以及评估其中哪些模型适合特定数据集的方法。有关应考虑的各个参数模型属性的进一步详细信息,可在 Collet (2003)⁴ 中找到,其中包括风险函数、生存函数和概率密度函数的图表,这些图表展示了不同模型根据其参数可以呈现的各种形状。风险函数是指在存活至时间 t 的条件下,在时间 t 的事件发生率。生存函数是指生存时间大于或等于时间 t 的概率,等同于 1 – F(t),其中 F(t) 是概率密度函数(注:此处原文表述为概率密度函数,但在统计学中 F(t) 通常指累积分布函数),表示生存时间小于 t 的概率。
①指数(Exponential)分布
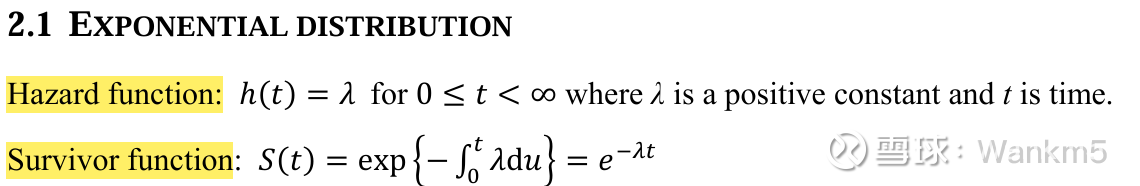
风险函数:h(t) = λ,其中 0 ≤ t < ∞,此处 λ 为正数常量,且 t 为时间。
生存函数:S(t) = exp{-∫0^t λ du} = e^{-λt}

指数分布是最简单的参数模型,因为它包含一个随时间推移保持恒定的风险函数,因此它只有一个参数 λ。指数模型是一个比例风险模型,这意味着如果在模型中考虑两个治疗组,其中一组个体在任何时间点发生事件的风险,与另一组类似个体发生事件的风险成正比——治疗效果通过风险比来衡量。评估备选参数分布适用性以及比例风险假设有效性的方法将在下文详细探讨,但如果要使用指数分布,重要的是要考虑风险在整个生命周期中是否可能保持恒定。
②威布尔(Weibull)分布

风险函数及生存函数如上图所示。其中,λ 为正值且是尺度参数(scale parameter),γ 为正值且是形状参数(shape parameter)。

威布尔分布既可以参数化为比例风险模型(如上述生存函数所示),也可以参数化为加速失效时间模型(accelerated failure time model)。在加速失效时间模型中,当比较两个治疗组时,治疗效果表现为加速因子的形式,该因子在时间尺度上起乘数作用。威布尔模型依赖于两个参数——形状参数和尺度参数。威布尔分布比指数分布更灵活,因为其风险函数可以单调递增或单调递减,但它不能改变方向。指数分布是威布尔分布的一个特例,即当 γ = 1 时。当 γ > 1 时,风险函数单调递增;当 γ < 1 时,风险函数单调递减。在考虑威布尔分布的适用性时,必须考虑单调风险假设是否成立。
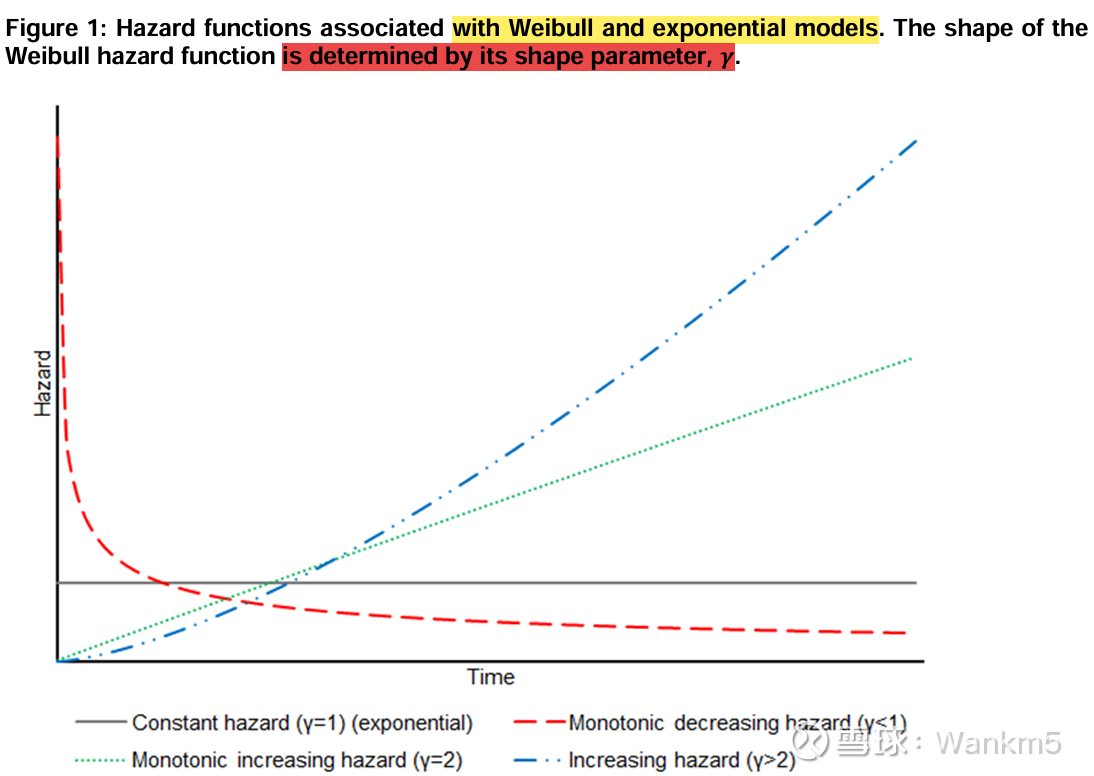
③贡佩尔茨(Gompertz)分布
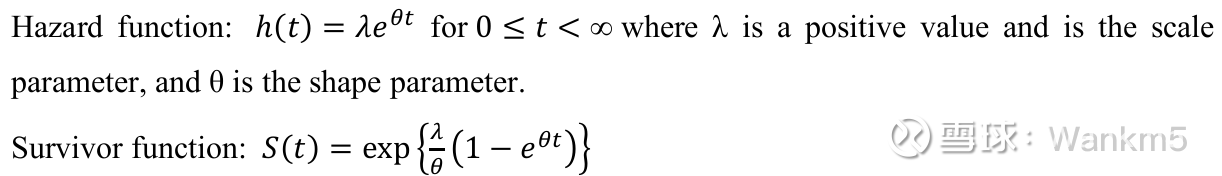
风险函数及生存函数如上图所示。其中,λ 为正值且是尺度参数(scale parameter),θ 是形状参数(shape parameter)。

与威布尔分布类似,贡佩尔茨分布有两个参数——一个形状参数和一个尺度参数。同样与威布尔分布类似,贡佩尔茨分布中的风险单调递增或递减。当 θ = 0 时,生存时间呈指数分布;当 θ > 0 时,风险随时间单调递增;当 θ < 0 时,风险随时间单调递减。贡佩尔茨分布与威布尔分布的不同之处在于,它的对数风险函数(log-hazard function)随时间呈线性变化,而威布尔分布则随时间的对数呈线性变化。此外,贡佩尔茨模型只能参数化为比例风险模型。在考虑贡佩尔茨分布的适用性时,必须考虑单调风险假设是否成立。
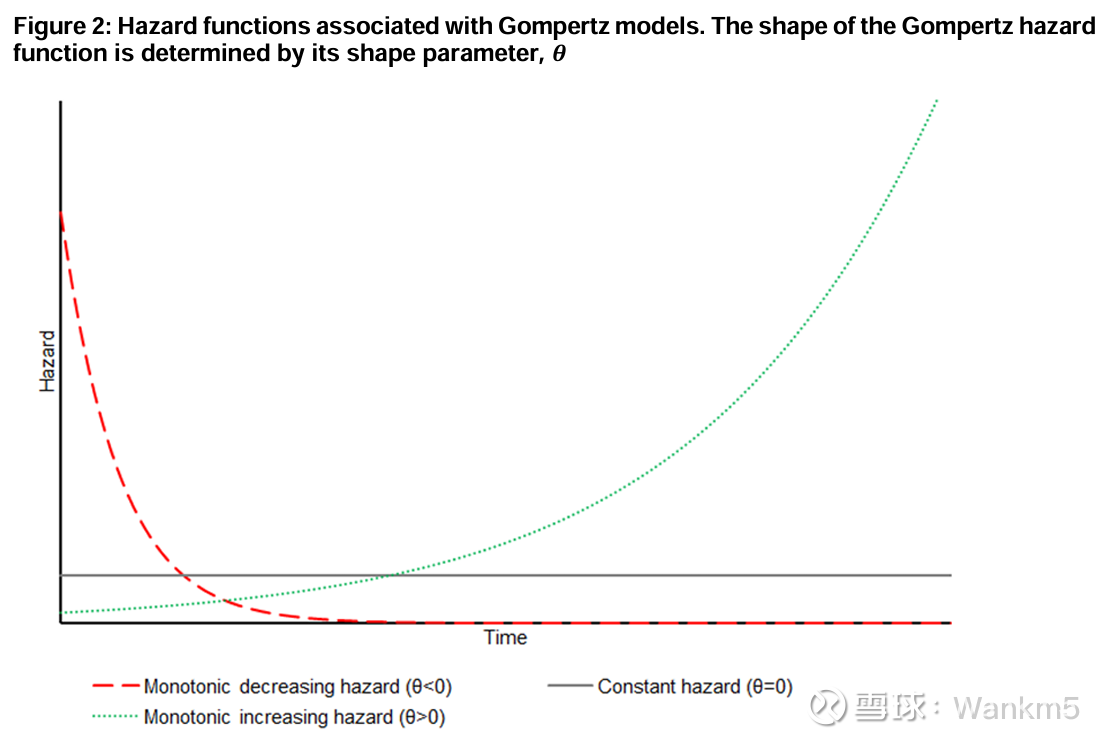
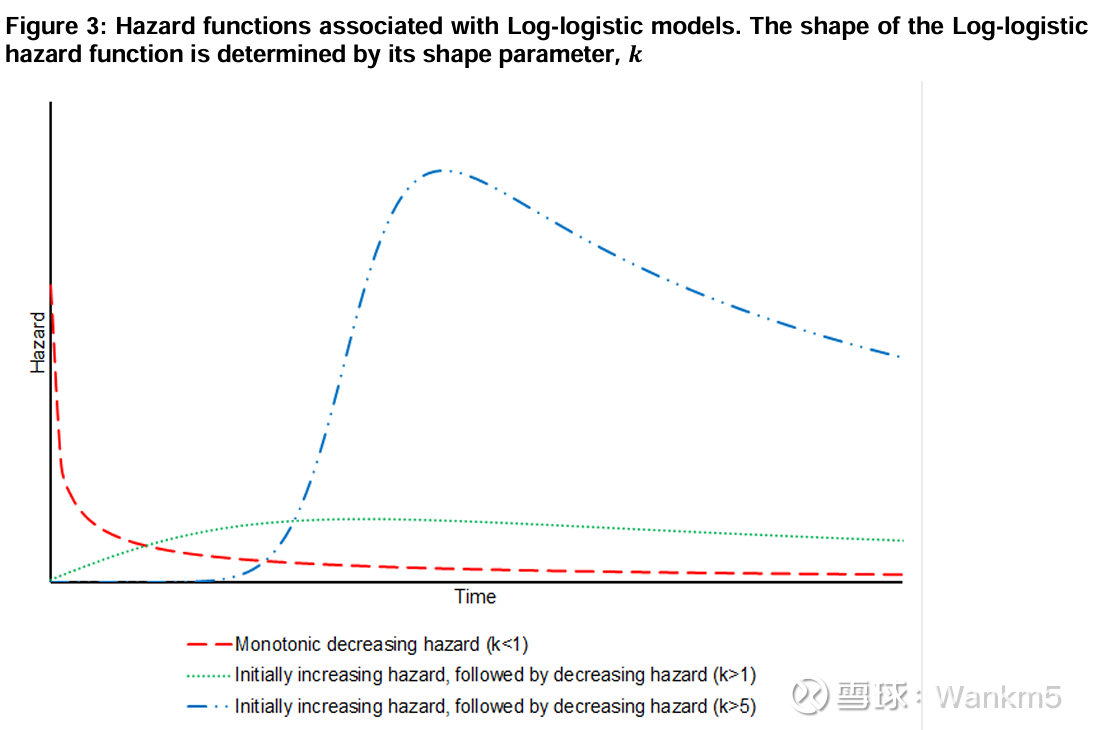
④对数逻辑(Log-logistic)分布
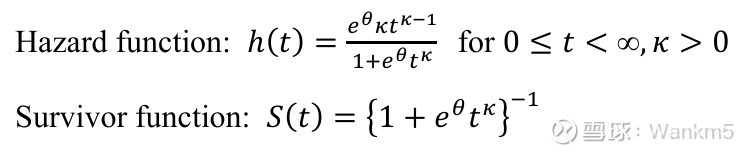
风险函数及生存函数如上图所示。

对数逻辑分布是一种加速失效时间模型(accelerated failure time model),其风险函数随时间的变化可以是非单调的。它有两个参数,θ 和 κ。如果 κ ≤ 1,风险随时间单调递减;但如果 κ > 1,风险具有单峰特征(single mode),即风险最初上升,随后下降。在考虑对数逻辑分布的适用性时,必须考虑非单调风险是否成立。由于其函数形式,对数逻辑模型通常会导致生存函数中出现长尾(long tails),如果要使用此类模型,也必须考虑到这一点。
⑤对数正态(Log-normal)分布
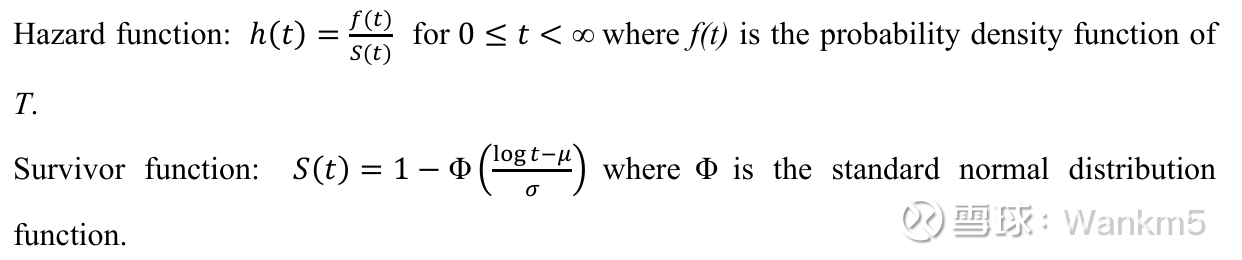
风险函数及生存函数如上图所示。其中 0 ≤ t < ∞,f(t) 是 T 的概率密度函数; Φ 是标准正态分布函数。


对数正态分布与对数逻辑分布非常相似,具有两个参数:μ 和 σ。风险最初增加至最大值,随后随着 t 的增加而减小。逻辑分布和正态分布之间的相似性意味着,对数逻辑模型和对数正态模型的结果可能是相似的。与对数逻辑模型一样,在考虑对数正态分布的适用性时,必须考虑非单调风险的合理性,并且必须考虑生存函数中可能存在的长尾效应的合理性。
⑥广义伽马(Generalised Gamma)分布

风险函数及生存函数如上图所示。其中 f(t) 是 T 的概率密度函数;Γ_{λt}(ρ) 被称为不完全伽马函数。

广义伽马分布是一个灵活的三参数模型,包含参数 λ、ρ 和 θ。它是双参数伽马分布的推广,其用处在于它包含了威布尔分布、指数分布和对数正态分布作为其特例,这意味着它可以帮助区分不同的备选参数模型。θ 是分布的形状参数,当其等于 1 时,广义伽马分布等同于标准伽马分布。当 ρ 等于 1 时,该分布与威布尔分布相同;而随着 ρ 越来越接近无穷大,该分布会变得越来越类似于对数正态分布。因此,当拟合广义伽马模型时,所得到的参数值可以表明威布尔模型、伽马模型或对数正态模型是否可能适用于所观测到的数据。
⑦分段(Piecewise)模型


分段参数模型在卫生技术评估中是一种未被充分利用的建模方法。这些模型比单一参数模型更灵活,并为模拟可变风险函数提供了一种简单的方法。它们通常被称为分段常数模型(piecewise constant models),因为通常会将指数模型拟合到不同的时间段,且每个时间段具有恒定的风险率。⁶ 分段常数模型对于模拟随时间观察到风险发生变化的数据集特别有用。除了指数模型之外的其他模型也允许风险随时间变化,但在威布尔和贡佩尔茨模型中,风险必须是单调的;而在对数逻辑和对数正态模型中,风险是单峰的。分段常数模型不会以这种方式限制风险。然而,这些模型对于生存曲线的外推部分不太有用,因为在这一部分中无法观察到风险。因此,作为分段常数模型的替代方案,可以考虑对生存曲线的外推部分使用不同的参数模型(例如威布尔、贡佩尔茨、对数逻辑、对数正态或广义伽马模型),不过,如果认为以恒定风险率进行外推是合适的,也应当考虑使用指数模型。下文将探讨如何利用外部数据和信息,来辅助决定哪种参数模型最适合用于长期外推。
关于以上模型的风险函数和生存函数的公式大家简单浏览一遍即可,后续建模会在该基础上再进一步展开。
⑧建模方法


当将参数模型拟合到生存数据时,可以采取两种主要方法。一种选择是拆分数据,并对每个治疗组分别拟合单独的或分段的参数模型。第二种选择是不拆分数据,而是对整个数据集拟合一个参数模型,在分析中将治疗组作为协变量纳入,并假设比例风险。所采取的方法通常很可能反映了正在进行的比较的性质。
当存在多个在不同的随机对照试验(RCTs)中评估过的对照组时,通常会依赖汇总统计数据,这本身就适合使用风险比的比例风险建模方法。在这种方法下,将风险比(HR)应用于基础生存曲线,以比较实验性治疗与对照组,从而将所有治疗方法与一个共同的对照组进行比较。如果将单一的HR应用于整个建模期间,则必须做出比例风险假设——即治疗效果随时间成比例,并且拟合到每个治疗组的生存曲线形状相似。该方法可用于比例风险模型(如指数模型、贡佩尔茨模型或威布尔模型),但对数逻辑模型和对数正态模型是加速失效时间模型(accelerated failure time models),它们不产生单一的风险比(HR),因此比例风险假设不适用于这些模型。然而,仍然可以在这些模型中使用治疗组作为协变量进行建模,此时治疗效果被测量为“加速因子(acceleration factor)”而不是HR。


通常,当可获得患者个体级别的数据时,就没有必要依赖比例风险假设并应用比例风险建模方法——应该对该假设进行检验,这将表明是分别对每个治疗组拟合参数模型更好,还是允许随时间变化的风险比更好。对每个治疗组分别拟合参数模型涉及的假设较少,尽管这也需要估计更多的参数。虽然对各个治疗组分别拟合参数模型可能是合理的,但必须注意的是,对不同的治疗组拟合不同类型的参数模型(例如,一个治疗组使用威布尔模型,另一个使用对数正态模型)将需要充分的理由证明其合理性,因为不同的模型允许形状差异很大的分布。因此,如果比例风险假设似乎不合适,最明智的做法可能是拟合相同类型的独立参数模型,允许对参数分布的形状和尺度参数都产生二维的治疗效果。⁹
如果使用比例风险模型,则应证明比例风险假设和治疗效果持续时间假设的合理性(使用下文描述的方法)。此外,应注意确保,仅将从所选参数模型获得的HR应用于对照组生存曲线(该曲线源自将治疗组作为协变量拟合的参数模型)——在理论上,应用来自不同参数模型或来自Cox比例风险模型的HR是不正确的。¹⁰ 当建模基于汇总数据而不是患者个体级别数据时,这会产生实际影响,因为所引用的HR的来源可能并不清楚。预计此问题将在未来审议证据综合和生存分析的TSD(技术支持文件)中予以考虑。
三、评估生存模型的适用性

在评估每个拟合模型的适用性时,可以而且应该使用多种方法。下面简要介绍了一系列可能有用的方法。这并不打算成为一份详尽的清单,因为其他一些统计检验可能也有用(例如,对残差的检验,如 Cox-Snell 残差、Martingale 残差或 Schoenfeld 残差),但下面列出的方法可能特别相关。评估备选生存模型的适用性,重点在于证明模型是否合适,其定义在于模型是否能够很好地拟合观察到的数据,并且外推部分在临床和生物学上是否具有合理性。仅满足其中一个标准的模型很可能是不合适的。
①目测检查

通过观察参数生存模型在视觉上与 Kaplan Meier 曲线的吻合程度,来评估其与临床试验数据的拟合优度通常很有用。这提供了一种简单的方法,借此可以选择一个模型而不是另一个模型。然而,这种评估方法具有不确定性,并且可能不准确。如果删失很严重,并且观察到的数据点聚集在 Kaplan Meier 曲线的某些点上,那么参数模型在某一段紧密跟随 Kaplan Meier 曲线,而在另一段则不然,这可能是非常合理的——这种情况并不一定意味着模型不合适。此外,拟合模型可能紧密跟随 Kaplan Meier 曲线,但可能具有不合理的尾部(例如,这可以通过使用外部数据或通过临床专家的意见来确定)。因此,使用这种方法来评估参数模型的适用性时应谨慎,并应补充其他测试。
②对数-累积风险图

在考虑合适的参数模型时,考虑随时间观察到的风险率很重要。不同的参数模型包含不同的风险函数。指数模型仅在观察到的风险近似恒定且非零时才适用。威布尔和贡佩尔茨模型包含单调风险,而对数逻辑和对数正态模型可以包含非单调风险,但通常由于在某一点之后风险随着时间的推移而降低,从而具有长尾效应。更多详细信息可从各种统计出版物中获得,包括 Collett (2003)。⁴
可以构建对数-累积风险图来说明在临床试验中观察到的风险。这些图表允许检查风险是否可能是非单调的、单调的或恒定的。此外,这些图表还允许评估比例风险假设(这是比例风险建模技术的基础)是否合理。图表还显示了观察到的风险发生显著变化的位置,这在考虑分段建模方法中针对不同时间段使用不同参数模型时非常有用。标准对数-累积风险图(绘制:log(-logS(t)) 对 log(t))用于测试威布尔和指数分布的适用性。这种方法的变体可用于测试贡佩尔茨、对数正态和对数逻辑分布的适用性。同样,更多详细信息可在 Collett (2003) 中找到。⁴
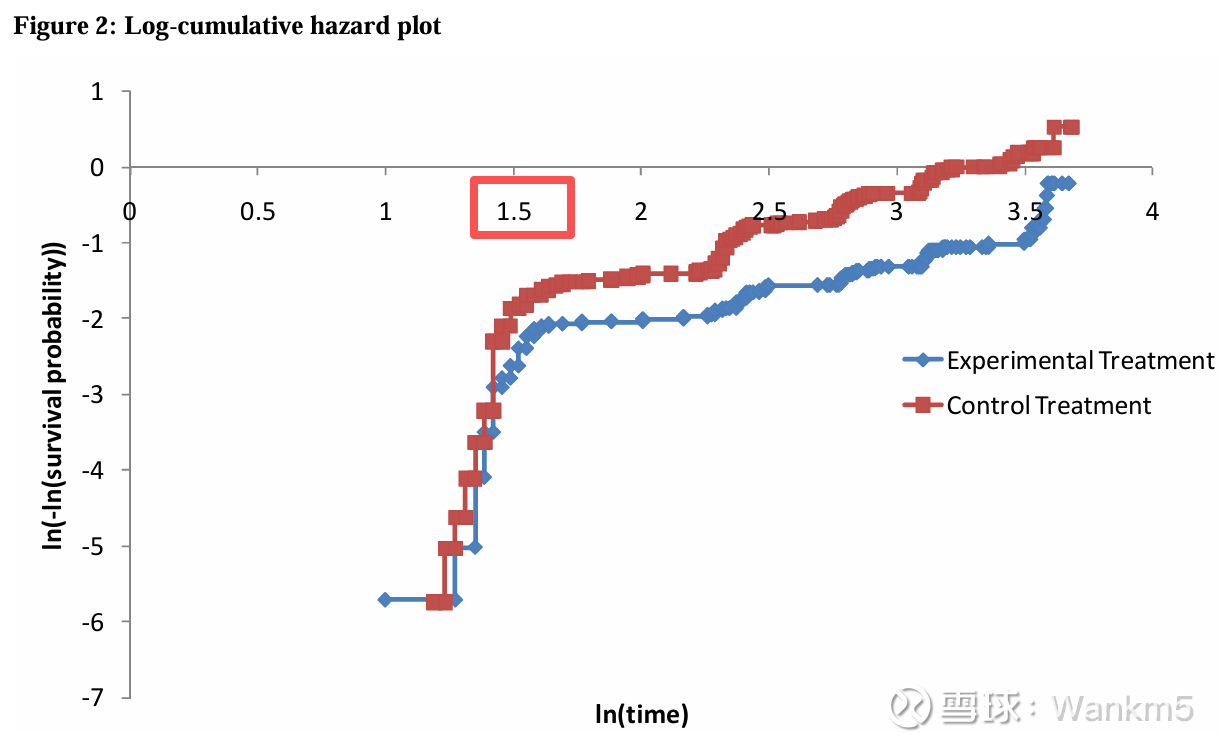

图 2 显示了先前在图 1 中展示的 Kaplan Meier 曲线的对数累积风险图的示例。它表明在大约 5 周 exp(1.5)后,风险出现了看似重要的变化,但两个治疗组之间的风险具有合理的比例关系。这表明单个参数模型可能不适合对生存进行建模,尽管在 5 周时间点之前观察到的风险(以及图中较后出现的“阶梯”)至少可以部分地用区间删失来解释。实验组在 5 周后图表的梯度似乎小于 1,因此指数模型不太可能适用。在 5 周之后,图表的梯度相当恒定,因此在这个时间点之后可能适用威布尔模型,尽管实验治疗图在随访结束时变陡,这值得进一步调查。应使用对数-累积风险图的变体来测试其他参数模型的适用性。
③AIC/BIC检验


赤池信息准则 (AIC) 和贝叶斯信息准则 (BIC) 为备选参数模型的相对拟合优度提供了有用的统计检验,它们通常可作为统计软件的输出结果获得。有关这些的进一步细节可从 Collett (2003) 获得。⁴ 诸如负 2 对数似然 (-2 log likelihood) 等指标仅适用于比较嵌套模型,即一个模型嵌套在另一个模型中(例如,一个模型与另一个模型相比增加了一个额外的协变量)。使用不同概率分布的不同参数模型不能相互嵌套。因此,负 2 对数似然检验不适合评估备选参数模型的拟合度,并且在过去的 NICE 技术评估 (TAs) 中曾被错误使用。AIC 和 BIC 允许比较不必嵌套的模型,其中包含一个惩罚使用不必要协变量的项(这些在 BIC 中的惩罚更高)。通常,在随机对照试验 (RCT) 背景下的生存建模中,没有必要包含协变量,因为可以预期任何重要的协变量都会通过随机化过程得到平衡。然而,某些参数模型比其他模型拥有更多的参数,AIC 和 BIC 会考虑到这些——例如,指数模型只有一个参数,因此在比较时,像威布尔或贡佩尔茨模型这样的双参数模型会受到惩罚。因此,AIC 和 BIC 统计量权衡了模型拟合度的提高与额外参数的可能低效使用,相对于 AIC,BIC 对额外参数的使用给予了更高的惩罚。
④上述方法的局限性

适用于目测检查、对数-累积风险图和 AIC/BIC 检验的一个重要局限性在于,它们都仅基于参数模型与观测数据的相对拟合度。虽然这很有用,因为确定哪些模型最符合观察到的数据很重要,但它并没有告诉我们参数模型在最终试验随访之后的时间段内有多合适。换句话说,上述测试解决了拟合模型的内部效度,但没有解决其外部效度。考虑到生存曲线外推部分通常对平均值估计产生的影响,这一点非常重要,并表明在评估备选模型的适用性时不能仅仅依赖这些指标——事实上,我们使用参数模型的原因正是为了估计曲线的外推部分。如果在很长一段时间内有大量的临床试验生存数据,那么假设一个能很好拟合数据的参数模型也能很好地外推试验数据可能是合理的。此外,当生存数据相对完整时,外推部分对曲线下总平均面积的贡献可能很小,在这种情况下,对数-累积风险图和 AIC/BIC 检验结果可能特别有用。然而,当生存数据需要大量外推时,重要的是尝试通过其他方法来验证拟合模型所做的预测。
⑤临床效应与外部数据

评估参数生存模型外推部分合理性的一种潜在有用方法是使用外部数据和/或临床效度。外部数据可以来自具有更长随访期的类似患者群体的单独临床试验,或来自相关患者群体的长期登记数据。如果可以从这些来源获得患者级别的数据,从而可以专门针对包含在新干预临床试验中的患者人群估计长期生存率,这将构成一个强有力的信息源。顺着这个思路,Royston、Parmar 和 Altman (2010) 提供了使用外部数据集对拟合模型进行外部验证的方法。¹²
如果无法访问患者级别的数据,此类信息只能是指示性的,但这仍然比完全没有信息要好。例如,如果注册表指出某种特定疾病的 5 年生存率为 10%,那么导致 5 年生存率为 0% 的参数模型可能是不合适的,那些估计 5 年生存率为 40% 的模型也可能是不合适的。更正式地说,可以寻找来自外部数据源的患者级别数据,以便完成更准确的长期生存建模,或者可以使用外部数据将拟合模型校准到长期数据点。然而,使用任何外部数据都需要平衡考虑,任何差异是否可能是由于外推不当或外部信息来源的局限性造成的。

很可能只有对照组治疗才有长期外部数据,因为根据定义,实验性干预是新的。因此,外部数据可能有益于为对照组治疗的外推提供参考,但对于估计新干预措施的长期生存率可能帮助较小。因此,需要对治疗效果持续时间等问题做出临床上有效且合理的假设,以便对实验性治疗的长期生存率进行外推。这些可以通过临床专家的意见和生物学合理性来提供依据,并且这些假设应该接受情景敏感性分析。
当需要进行大量外推时,应常规寻找更长期的生存证据和/或获得临床专家对预期长期风险的判断。
四、实战:基于HARMONi-A IPD数据的参数模型选择
很多人看临床数据只盯mOS或mOS的HR值,但这对于像 AK112 这样带有PD-1免疫机制的创新药来说,仅仅是前50%患者的及格线。这座金矿真正的估值底牌,藏在后50%的“长尾”里。为了精准推演这部分长尾价值,我们利用生物统计学界最严苛的标准参数模型,对HARMONi-A试验重构后的个体患者数据(IPD)进行了一场客观的数学海选。
首先,我们直接排除了最常见的指数分布模型(Exponential)。该模型假设病人的死亡风险是恒定不变的,这在肿瘤免疫治疗中极其荒谬,因为随着“免疫记忆”的苏醒,患者后期的死亡风险会发生动态的下降。
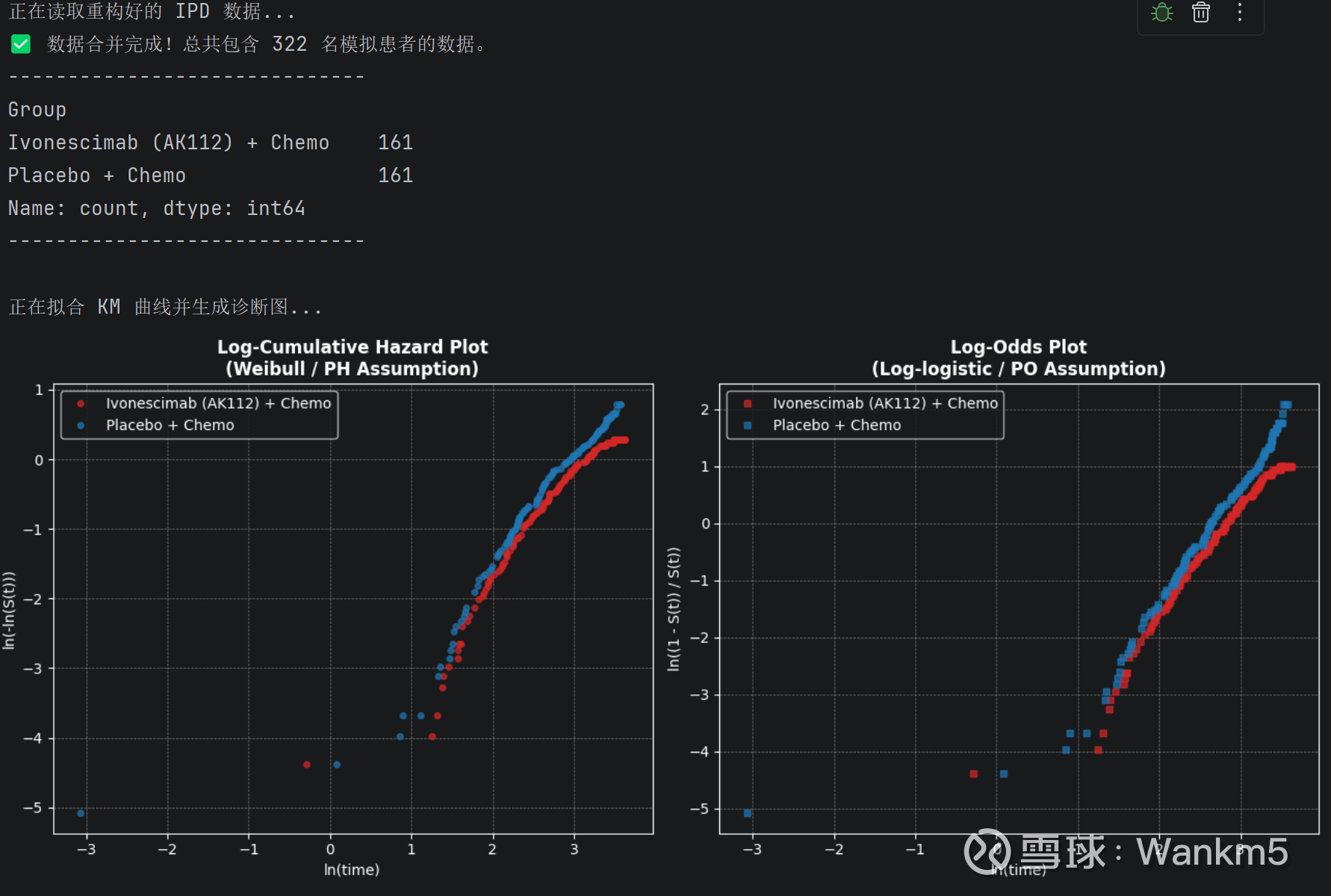
在具体的模型博弈中,我们重点检验了威布尔(Weibull)与对数逻辑(Log-logistic)模型。通过观察对数累积风险图的线性收敛程度,并引入统计学裁判AIC与BIC法则(赤池/贝叶斯信息准则)进行客观打分,我们试图寻找在“精准拟合”和“不过度包装”之间平衡度最高的基准模型。
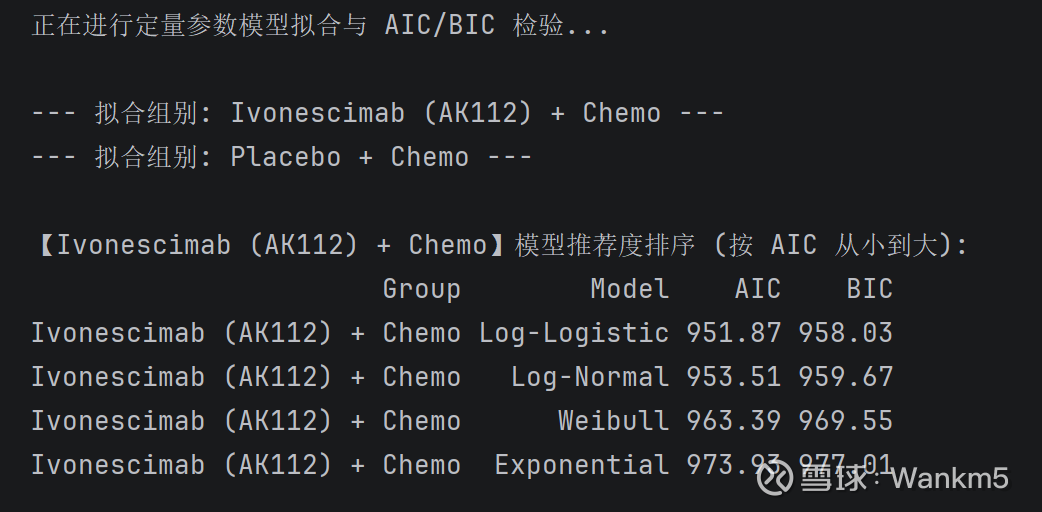
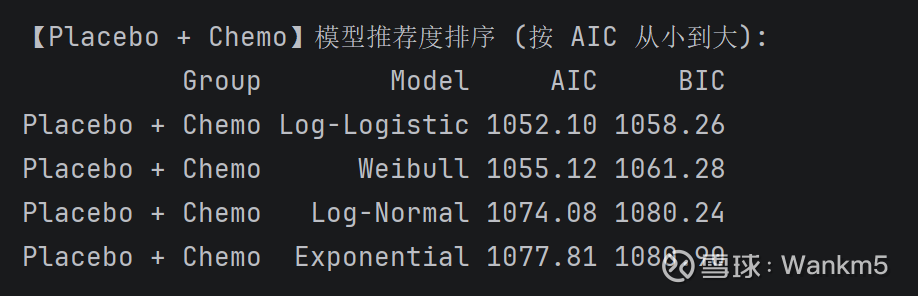
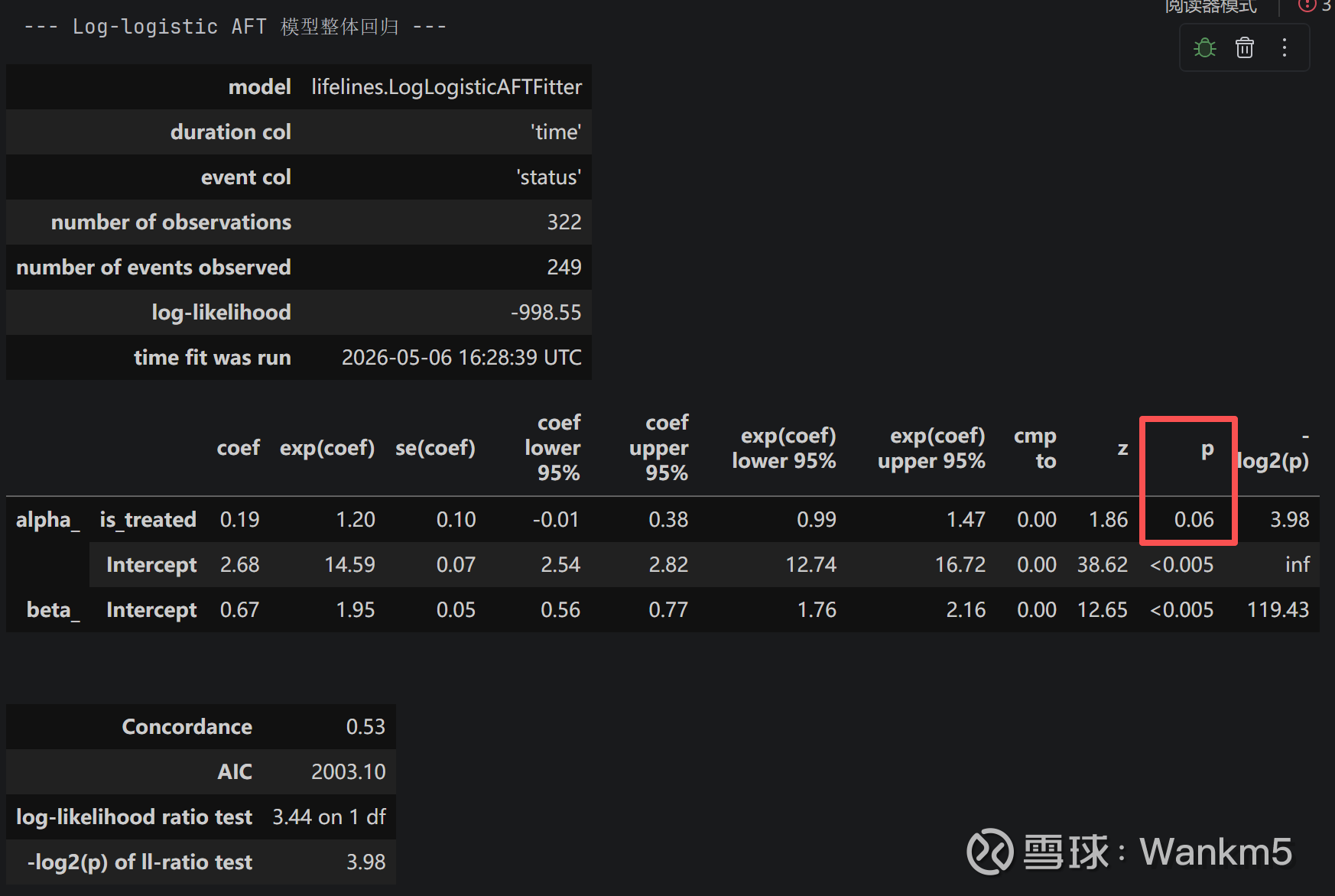
尽管在量化筛选中,对数逻辑模型凭借最低的AIC/BIC得分脱颖而出,但深入的参数检验揭示了其在拟合生存数据时的底层局限。一方面,数据显示依沃西组与对照组的形状参数(β)存在显著差异(1.84 vs 2.06),这在诊断图尾部直观表现为明显的“非平行弯曲”。

另一方面,整体 AFT 回归模型的预测区分度极弱(Concordance 仅为 0.53,几近随机),且尽管提示了生存时间延长约 20% 的获益趋势(时间比 TR=1.20),其结果却仅处于边缘显著区间(p=0.06)。
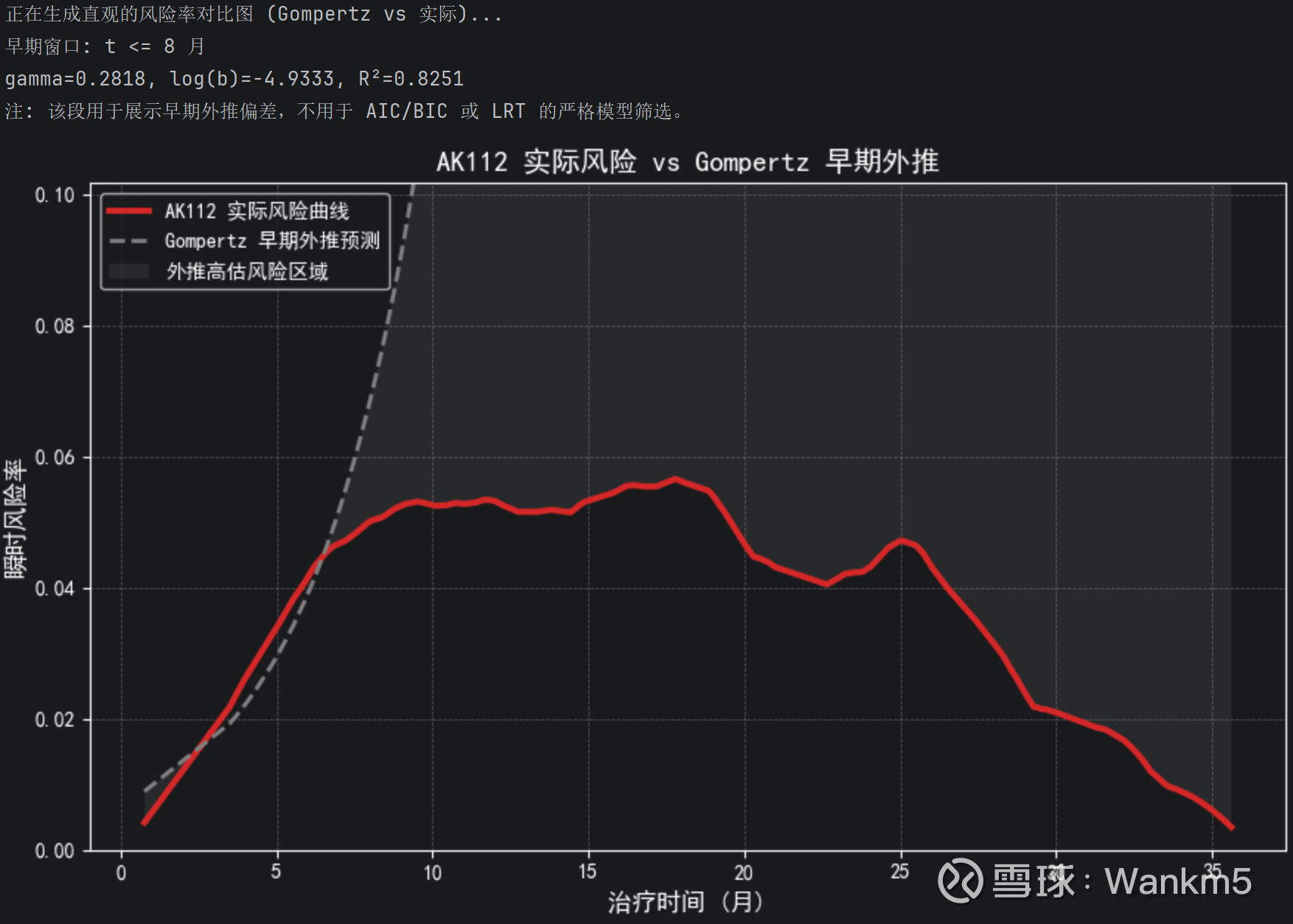
这一统计学偏差的根源,正是双抗/免疫疗法(IO)典型的“拖尾效应”——随着观察时间推移,长生存获益人群的出现本质上打破了传统模型在全局保持成比例几率(PO)或等比例风险(PH)的理论假设。
我们进一步通过动态风险对比图,测试了传统药企常用的贡佩尔茨模型。该模型依据患者前期的恶化趋势,机械地预测死亡/进展风险会随时间呈指数级飙升(图中灰色虚线)。然而,真实的风险曲线显示,AK112 患者在挺过前期的危险期后,瞬时风险不但没有飙升,反而明显掉头向下并趋于平缓(图中红色实线)。传统模型在后期的严重“失真”(图中大面积的误差阴影),恰恰从底层数据反向印证了 AK112 打破常规的强大“免疫长尾”获益。
为了彻底摒弃主观偏见,我们最终引入了没有任何固定形状的广义伽马(Generalized Gamma)模型。这是一种依靠核心参数“Q”来自我变形的硬核检验方式。通过观察跑出的Q值95%置信区间(例如包含1则退化为威布尔,包含0则变为对数正态),我们让底层数据自己选出了最合身的长期外推形态。
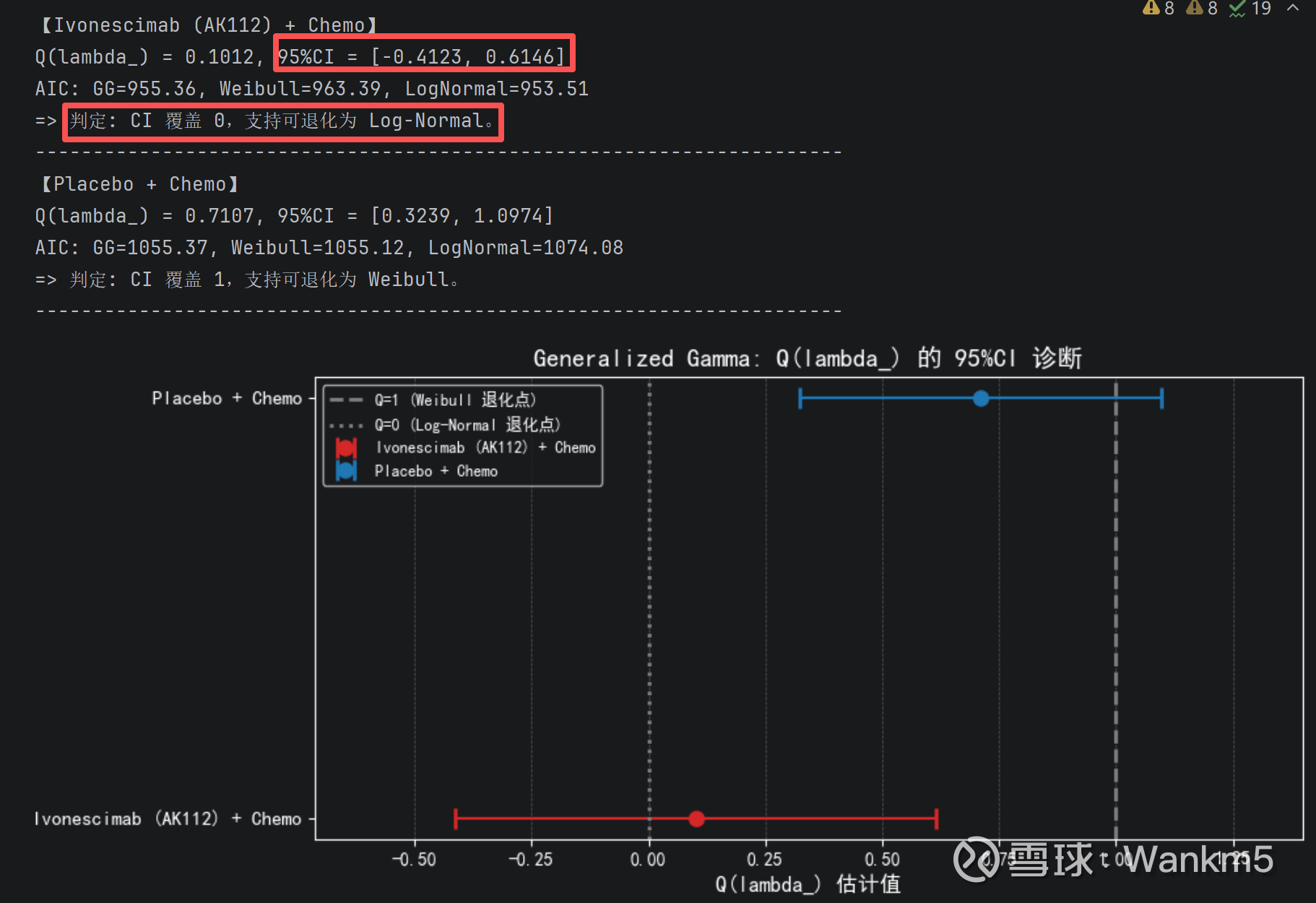
对于带有双重机制的 AK112 实验组而言,其真实的死亡风险并非恒定,而是在度过前期危险后,随“免疫记忆”苏醒呈现出动态下降的平缓长尾;尽管广义伽马检验显示其底层的自然分布倾向于对数正态形态,但结合前述苛刻的AIC/BIC评分来看,这类单一的全局标准参数模型依然无法实现最优拟合。
———————————————————————————————————————
回顾我们在HARMONi-A上的拟合过程,即便是经过严苛AIC/BIC筛选的最优全局参数模型,在刻画免疫疗法复杂的“非比例风险”与“长尾效应”时,也依然面临着被尾部数据拉扯的局限。这不仅印证了引入弹性样条(Splines)或分段框架等高阶工具的必要性,也为我们抛出了一个更具技术挑战性的命题:
既然在OS数据相对成熟的HARMONi-A上,“一根曲线拉到底”的单一模型尚且捉襟见肘,那么面对完全没有OS数据的极端场景,我们该如何进行前瞻性的推演?
这正是HARMONi-6试验带给我们的硬核考验。目前,该试验仅公布了极具统治力的PFS数据(中位11.14个月 vs 6.9个月,HR=0.60)。要在OS盲盒揭晓前,仅凭PFS跨越推导其长期的总生存获益,传统的参数拟合思路将彻底失效。
我们必须动用更高维度的建模体系:一方面,需要依靠多状态生存分析(如卷积运算),在底层数学逻辑上实现从PFS向OS的跨越;另一方面,必须采用分段模型(Piecewise Model)精准还原真实临床方案中“24个月硬性停药”的干预规则。即在前24个月,用独立分布去捕捉靶向与免疫双机制带来的高强度获益;而在24个月后,无缝拼接一种更为平缓的衰减模型,以模拟停药后纯靠“免疫记忆”维持的长尾平台期。
后续,我们将以HARMONi-6为实战案例,深入拆解这套融合了状态转移与分段切割的进阶算法,探讨如何通过严密的底层统计学逻辑,提前勾勒出创新药真实的长期生存护城河。
@雪球创作者中心 #雪球星计划# $康方生物(09926)$ $再鼎医药(09688)$ $再鼎医药(ZLAB)$
本话题在雪球有27条讨论,点击查看。
雪球是一个投资者的社交网络,聪明的投资者都在这里。
点击下载雪球手机客户端 http://xueqiu.com/xz]]>
#不止于HR值生存曲线外推的理论框架标准参数模型与部分实战一