北大、银河通用等团队提出LDA-1B 模型,让“非标准”数据,成为机器人理解世界的关键
本文来自微信公众号: 42号电波 ,作者:兰博,编辑:James,原文标题:《北大、银河通用等团队提出 LDA-1B 模型,让「非标准」数据,成为机器人理解世界的关键》
过去一两年,机器人基础模型的进展,很大程度建立在行为克隆这条路径上。通过收集大量专家示范数据,模型可以在多个操作任务上达到可用水平,这一点已经在抓取、搬运等标准任务中得到验证。
不过当数据规模继续扩大,更具体的问题开始出现了,模型见过越来越多的动作,但仍然难以利用那些非标准的交互数据。这些数据中包含了物体如何运动、接触如何发生等关键信息,但在以行为克隆为主的训练范式下,往往被直接丢弃。
尽管一些工作尝试用统一世界模型(UWM)的思路去整合这些数据,希望通过动力学建模来吸收更多信息,但在实际落地中也遇到了一些限制,比如数据的使用方式比较粗糙,不同来源的数据难以协同。还有就是数据集本身高度碎片化,缺乏统一结构,很难支撑模型规模的进一步扩大。
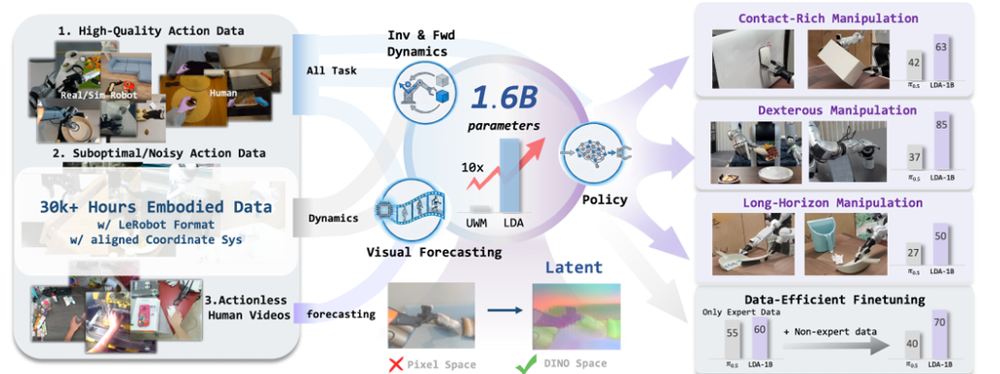
在这样的背景下,北京大学、银河通用等团队提出了隐空间世界动作基础模型LDA-1B,重新审视了数据在训练中的作用,通过通用具身数据摄入机制,让不同质量、不同形式的数据参与到统一建模中,并在隐空间中联合学习动力学、策略与视觉预测。

另外,配合一个标准化的大规模数据集EI-30k,以及基于多模态扩散Transformer的建模方式,模型可以在10亿参数规模下实现稳定训练,并在多类操作任务中表现出了更高的泛化能力。
这种变化其实并不局限于具体性能的提升,重点在于模型到底该如何看待「数据」和「世界」。
LDA-1B的核心是什么?
当前许多主流的机器人基模,多数都建立在行为克隆框架上。其基本假设是只要收集足够多的专家示范,模型就可以学会对应的动作策略。
只不过这种范式天然对数据质量非常敏感,但是高质量的数据获取成本又很高,遥操作、精确标注、对齐动作空间,这些也让数据规模难以真正扩大,即使是引入仿真数据,也容易受到现实差异的影响。
而且还有大量的「非标准数据」在这个过程中容易被忽略,比如没有动作标注的人类第一视角视频、动作噪声较大的低质量轨迹、不同机器人本体之间不一致的数据。

此外,更深层的问题在于表征方式,很多方法直接在像素空间预测未来状态,这会让模型过度关注视觉细节,比如光照、纹理、背景变化,而非真正关键的物理变化。这种耦合容易让模型:
-
更容易「记住外观」,并非「理解因果」。
-
泛化能力受限,尤其是在长时序任务中。
-
对接触、力反馈等复杂交互建模不足。
在机器人的落地部署,这种局限则会让机器人的动作变得不稳定。
对于上述问题,LDA-1B提出的核心不是简单的结构改进,重点是一整套训练逻辑的重构。
首先是统一隐空间动力学建模。模型不直接在像素空间预测未来,而是在基于DINO特征构建的隐空间表示中学习状态演化。这种做法可以减少对外观信息的依赖,使模型更关注哪些变化是由动作引起的。
其次是通用数据摄取机制,将不同类型数据赋予不同功能:
-
高质量数据:同时用于策略学习与动力学建模。
-
低质量轨迹:主要用于学习动力学。
-
无动作标注的人类视频:用于视觉预测。
在这个过程中,数据不再被简单筛选,会被「分工使用」。
这种调整的关键在于把「数据质量」从一个过滤条件,变成了一个建模维度。模型不再要求所有数据都具备完整监督,而是允许不同监督信号共同参与训练。
相比较传统方式,LDA-1B这种转向动力学驱动的策略,也让机器人开始逐渐理解世界的物理状态。
一个框架,同时预测动作与未来状态
在具体设计上,LDA-1B采用了一个较为复杂但逻辑一致的架构。模型核心是一个多模态扩散Transformer,同时对动作序列和未来视觉潜变量进行去噪预测,让策略学习与状态预测在同一框架内完成。
-
联合优化目标:包括策略、前向动力学、逆动力学和视觉预测。
-
异步对齐机制:视觉与动作流在时间上并不严格同步,通过共享注意力层进行融合。
-
隐空间表示:使用结构化DINO特征,避免像素冗余。

其中一个细节在于,模型通过「动作条件注意力」学习关注区域。论文中展示,模型在注意力可视化中呈现出对接触区域和运动方向的关注倾向,而忽略背景干扰。
这类机制在机器人行为方面,可以让动作决策更依赖物理交互而非视觉显著性,并且在任务中保持稳定和连续性。
同时,即便模型规模在扩展,但训练还能保持稳定,这也与扩散建模和隐空间表征的结合有关。
不过LDA-1B之所以能够扩展到基础模型规模,并不只依赖模型结构本身,更重要的是其配套的数据组织与训练方式。对此,团队构建的具身交互数据集(EI-30k),在这一点上起到了基础性作用。

EI-30k数据集规模总计超过3万小时,涵盖真实机器人、仿真、带动作标注的人类示范以及无动作人类视频四类数据。这些数据在质量、标注完整性上差异明显,但并未被严格筛除,而是保留并附加质量标签,使模型能够在不同保真度数据上共同学习。
而为了解决异构数据难以协同的问题,所有数据被统一转换为LeRobot格式,并在动作层面对齐到共享坐标系。此外,在训练上,预训练阶段冻结VLM与DINO编码器,仅更新动力学与策略相关模块。
在这个基础上,模型通过轻量级后训练直接使用未筛选的遥操作数据进行适配,无需依赖高质量专家示范,从而降低数据成本并提升实际可部署性。

「低质」数据反而带来提升?
在具体的实验上,团队在仿真和真实世界中进行了验证,包括接触密集操作、灵巧操作、长时序任务等方面。
真实世界实验中,LDA-1B分别被部署在配备二指夹爪的Galbot G1、装上灵巧手的Galbot G1(22自由度)、以及搭载BrainCo灵巧手(10自由度)的宇树G1上。
少样本适应阶段的结果表明,在简单抓取和放置任务上,LDA-1B的成功率达到了80%到90%,展示出了一定的跨本体迁移能力。

在清理垃圾的任务中,相比于GR00T-N1.6和π0.5,LDA-1B达到了35%的成功率。
其中有一个值得特别关注的发现来自数据效率实验,论文在此处挑战了一个普遍共识:低质量数据通常是负担,甚至会降低模型性能。
团队在仿真中构建了一个混合质量数据集,包含专家轨迹和次优轨迹(含暂停、重试、低效动作等)。实验中,仅使用高质量数据时,基线模型达到基础性能;而当LDA-1B在相同混合数据上进行后训练,竟然通过利用「低质量」轨迹额外实现了10%的性能提升。
这也意味着那些在过去被视为累赘的所谓「低质量」数据,在新的框架下反而成为动力学学习的差异化燃料,可以训练出一个对真实世界不规则性适应性更强的模型。
总体来看,LDA-1B带来的启发,其实是在认知层面的范式校正,那就是机器人模型不一定要盲目追求完美数据。
如果模型只能依赖干净数据,那么规模扩展会始终受限。所以LDA的做法提供了一种不同路径,即优化对于数据的利用方式。
而且更深层的取舍出现在方法论层面,LDA选择的是统一世界动作模型路线,试图在一个大模型里同时承载策略、动力学和视觉预测。
另一条可能路径是模块化系统,分别训练世界模型和策略再耦合。两条路径谁能走向收敛,目前还没有定论,但LDA的结果至少表明,在异构数据规模化的利用上,统一方案展现出了竞争力。
但这种方法也存在着一定的边界,比如论文中提到依赖固定的DINO视觉特征,且主要采用第一视角相机视角,这也可能会限制模型对新视觉视角和多模态信号的泛化能力。
从方法论上看,这项工作其实更接近一种系统级设计,并不是单点优化。它着重调整了问题的拆解方式,让数据、模型和任务之间的关系更加一致。
所以在机器人领域正处在从「学习动作」转向「学习物理规律」的赛道上,LDA在隐空间动力学上的探索也给了行业一个相对明确的参考。
项目主页:https://pku-epic.github.io/LDA/
论文链接:https://arxiv.org/pdf/2602.12215
#北大银河通用等团队提出LDA1B #模型让非标准数据成为机器人理解世界的关键