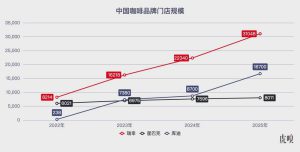
估值百亿美金的DeepSeek 走下神坛,走上长征
本文来自微信公众号: 岳涌大江流 ,作者:岳老狮
2026年的春天,中国AI圈最神秘的一张底牌,被推进了百亿美金的聚光灯。
很多投资人问我,DeepSeek到百亿美金是不是顶了?我回了他们一句话:如果只看跑分,那它已经到顶了;但如果看它在国产算力荒漠里种庄稼的能力,这100亿只是开垦费。
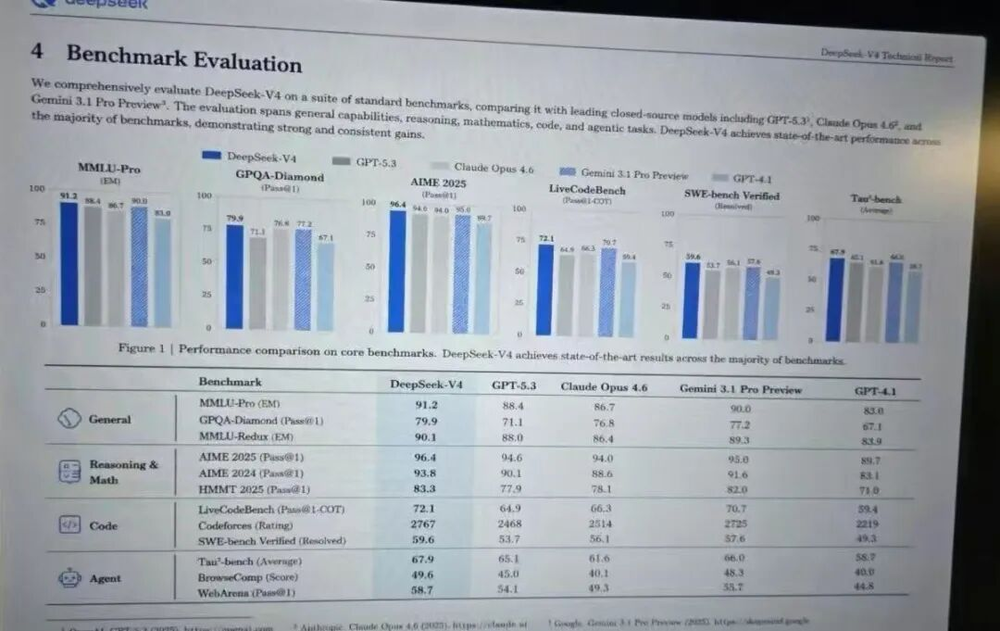
据The Information披露,DeepSeek正在洽谈一轮3亿美元融资,投后估值直指100亿美金。与此同时,DeepSeek-V4技术报告的Benchmark页面悄然流出。在亮马桥或是中关村的咖啡馆里,这张截图被不断放大、比对,伴随着关于“国产算力到底行不行”的低声争论——数字确实让人窒息:MMLU-Pro 91.2,力压GPT-5.3的88.4;AIME 2025 96.4,领先一众顶级闭源模型;SWE-bench Verified 59.6,代码工程维度同样拔得头筹。

但读懂这张图的人,不会只盯着柱状图的高低。
一、数字背后的“心脏移植”
V4为什么迟迟未正式发布?
据接近DeepSeek的人士透露,团队核心精力不在刷榜,而在底座大迁移——将万亿参数MoE架构,从英伟达CUDA生态整体迁移至国产算力栈(华为昇腾为代表)。
这在业内有一个残酷的比喻:给一个正在跳动的心脏换腔体。
在CUDA上跑出91.2的MMLU-Pro,不代表在华为昇腾上同样能复现。每一个算子、每一层注意力机制,都要重新校准。利,在于算力主权;弊,在于性能损耗不可预测。V4的推迟上线,本质是中国AI在为自己的底层安全“补课”——而这堂课,没有任何人交过作业。
二、刘翔式隐喻:神格的重量
中国互联网,正在把DeepSeek推向一个危险的位置。
自R1以“四两拨千斤”震惊硅谷后,DeepSeek就被赋予了某种“救世主”属性。这种期待,极像2008年前的刘翔:我们要求它每一步都破纪录,要求它用一己之力撑起整个国产大模型的尊严。
但现实逻辑冷酷:Codeforces Rating 2767,LiveCodeBench 72.1——这些数字固然耀眼,却掩盖不了一个事实:DeepSeek首先是一家公司,然后才是一个符号。
过度的“为国争光”叙事,只会让模型变形,让团队折损。中国AI在2026年真正需要的,不是一个活在聚光灯下的巨星,而是一个“平常的大模型”——足够稳、足够便宜、能扎进工业场景去写代码、跑Agent。这比任何Benchmark第一,都更有商业价值。
三、百亿估值的真正含义:Token工厂的入场券
100亿美元,是DeepSeek彻底告别“幻方量化私房菜”时代的分水岭。
外部资本进入,意味着对冲基金式的灵性探索,必须向工业化大规模生产转型。资本真正看中的,不是那几列柱状图,而是DeepSeek已验证的Token边际成本控制能力。
当硅谷还在为几美分的推理成本纠结时,DeepSeek的逻辑是——如果不能把Token成本打到电费级,大模型的商业化就是一场集体的自嗨。
AI的终局是“Token工厂”。当推理成本降低到如同电费般透明,谁拥有最高效的生产线,谁就是最终赢家。这100亿美金,是DeepSeek拿到的最后一张全球AI总决赛入场券——不是奖杯,是门票,是沉甸甸的起点。
尾声:在无人区,慢就是快
DeepSeek正在进入国产大模型真正的“无人区”。前方没有参照物,只有日益收紧的算力封锁,和步步紧逼的硅谷巨头。
对V4,我们不妨少一点道德绑架,多一点产品经理的耐心——给它时间去调优那个尚不完美的国产底座,给它空间去消化百亿美金带来的重量。
2026年,我们需要英雄,但更需要能走出手术室、继续跑下去的幸存者。V4不必成神,它只需成基。
#估值百亿美金的DeepSeek #走下神坛走上长征