
答案在风中飘:当我们谈论过拟合时,到底在谈什么
<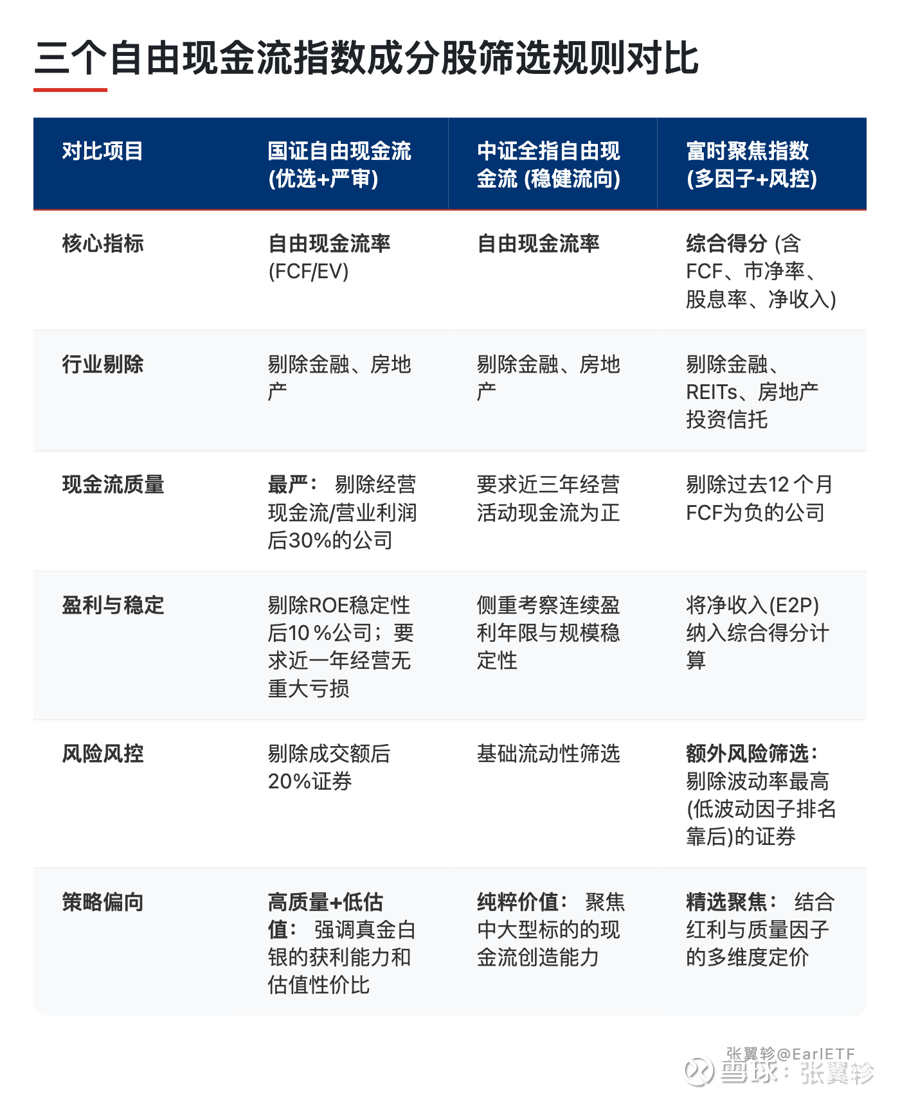
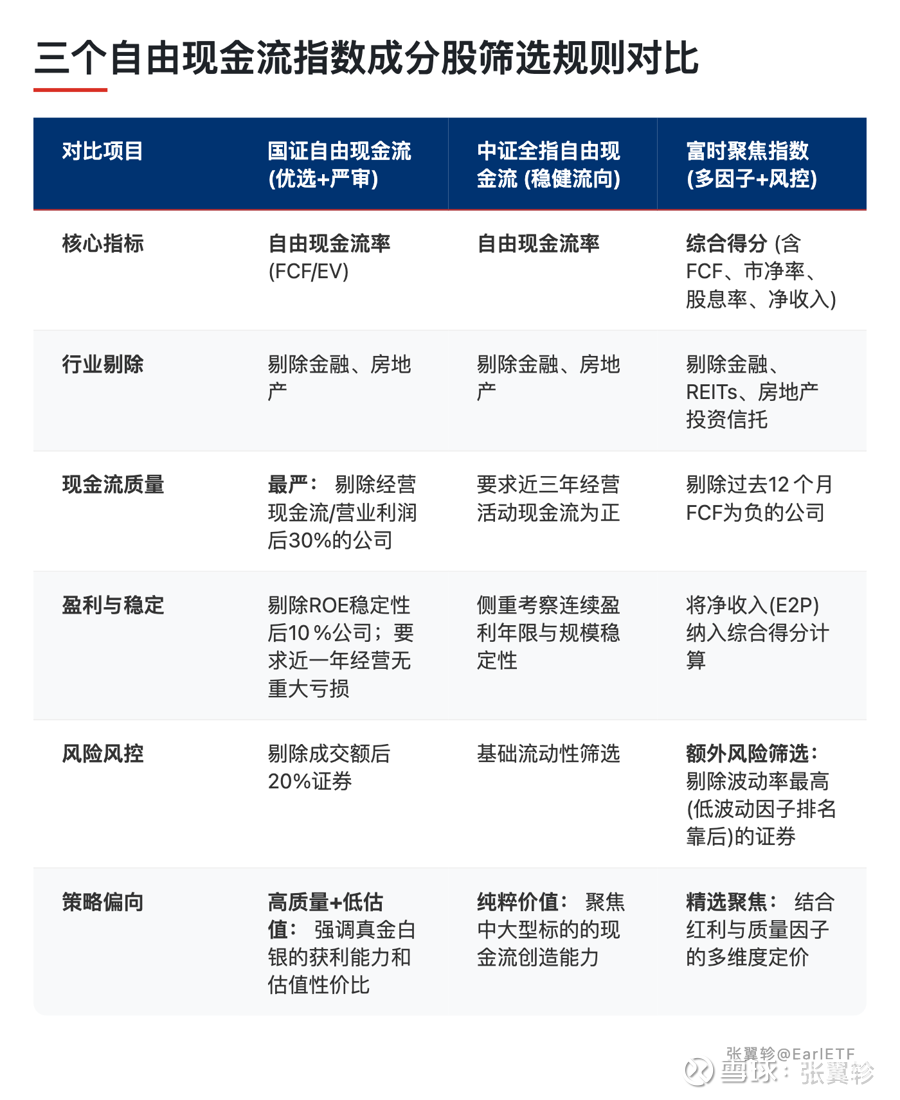
核心选股逻辑其实大同小异:在市场中,筛选自由现金流率优秀的公司。
当然,往往还有一些筛选规则,也是争议的来源。
第一,剔除金融和房地产行业。
这是被质疑最多的一条,但在我看来,恰恰是无需讨论的。
这不是 A 股指数的发明。美国最知名的自由现金流 ETF——Pacer US Cash Cows 100(COWZ),同样剔除了金融和房地产。这是自由现金流这个概念本身不适合金融地产,不是为了让回测更好看。
第二,设置了一些基本的质量筛选。
比如要求连续几年自由现金流为正、剔除 ROE 稳定性差的企业等。
这些条件的目的是排除那些现金流偶然为正但基本面堪忧的公司。你很难说 “要求一家公司持续赚钱才能入选” 是什么过度拟合 —— 这更像是常识。
把指数的编制规则摊开来看,也许我能力有限,没能看出有什么 “恰好” 让这些年的回测曲线变好看的神秘参数。
样本内的指数数据,必然不如样本外的数据来的可信,这就是为何我对中证红利指数一直情有独钟的原因,毕竟它用 2014 年以来的规则发布后数据证明了自己。
但是,当我们要讨论 “A 股的自由现金流指数是过拟合产物” 的时候,科学的精神,是要指明究竟怀疑哪一条规则,拟合了哪一段历史,以实现无法复现的超额。这样讨论才有延展的空间。
鲁棒性与样本外
在程序化交易领域,检验一个策略是不是过拟合,有一个经典方法:鲁棒性测试。
原理很简单。如果一个动量策略的核心参数是 20,你把它改成 19 或者 21,如果回测结果天差地别,那大概率是过拟合了。
反过来,如果参数在一个合理范围内小幅变动,结果依然稳健,那说明策略捕捉到的可能是真实的规律。学术论文里验证动量因子有效性,通常要求 3 个月、6 个月、12 个月等多个回看期都有效,而不是只在某个特定时长上灵验,就是这个道理。
自由现金流指数的情况呢?几个 A 股自由现金流指数的编制规则大同小异但细节各有不同 —— 选股范围不完全一样,过滤条件松紧有别,加权方式也有差异 —— 但长期回测的表现方向是一致的。这本身就是一种天然的鲁棒性验证:规则没有精确到只有一种写法才能出好结果。
当然,还有一个反过来的问题同样值得讨论 —— 样本外表现 “暂时不好看”,等于策略就是废物吗?
这里值得提一个例子。
杰里米・西格尔在 2005 年出版了《投资者的未来》,用大量美股历史数据论证高股息策略的优越性。然而书出版没多久,在次贷危机之后,美股就迎来了一轮延续至今的成长股浪潮,高股息策略在相当长的时间里跑输大盘,迄今还没回过劲。
如果按 “样本外不行就是过拟合” 的标准,西格尔的结论早该被扔进废纸篓。但没有人会这么做 —— 因为那本书基于的是百年美股数据,背后有扎实的理论支撑,而成长股的强势更多是特定时代背景(低利率、科技革命)的产物,并不能反过来否定股息策略的长期逻辑。
这恰好说明一个容易被忽视的问题:样本外短期落后,和过拟合,是两件完全不同的事情。
一个策略可能因为市场风格轮动、宏观环境变化而阶段性跑输,但只要它的逻辑根基还在,它就仍然值得关注。而过拟合的策略,根基本来就不存在。
所以,面对一个修订过规则的指数,与其条件反射式地喊出 “过拟合”,不如多问几个具体的问题:每一条规则有没有独立的逻辑支撑?参数是否鲁棒?海外有没有可对照的长期实践?
这些问题不难回答,只是需要耐心,同时内心不带偏见。
鲍勃・迪伦那首歌里,每一段追问的结尾都是同一句:The answer is blowin' in the wind. 很多人把这句话理解为 “没有答案”。但也许还有另一种读法 —— 答案一直都在,只是你得愿意在风里站一会儿,才接得住。
本话题在雪球有34条讨论,点击查看。
雪球是一个投资者的社交网络,聪明的投资者都在这里。
点击下载雪球手机客户端 http://xueqiu.com/xz]]>
#答案在风中飘当我们谈论过拟合时到底在谈什么