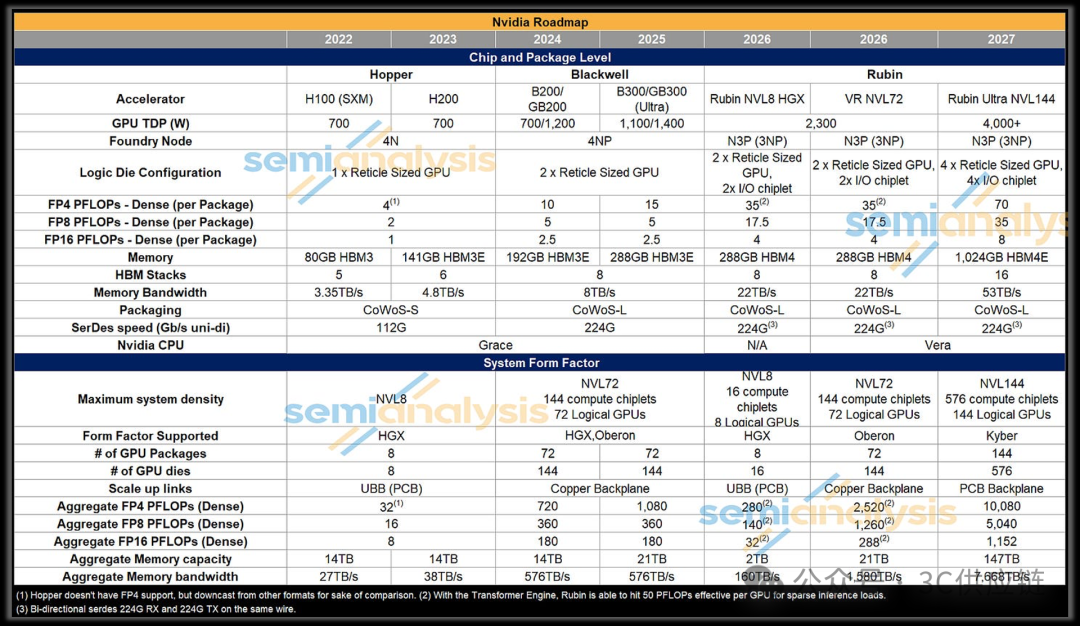
英伟达Vera Rubin NVL72服务器架构与供应链解析

<
随着大模型规模进入万亿参数级别,AI数据中心基础设施的形态正在发生变化。过去AI集群主要由大量独立服务器节点组成,每台服务器部署少量GPU,并通过数据中心网络互联。而在新一代AI架构中,系统正在向“机柜即计算机(Rack-Scale Computer)”演进。
Rubin NVL72正是这一理念下设计的系统。整柜内部集成:
Vera CPU
Rubin GPU
HBM4高带宽内存
NVLink 6 GPU互连网络
NVSwitch交换网络
200kW级液冷散热系统
整柜72颗GPU通过NVLink网络互联,可形成统一GPU计算域并共享显存资源,从而支持大规模AI模型训练与推理。多个NVL72机柜通过高速网络连接后,可以进一步构建AI集群,例如NVIDIA提出的SuperPOD系统。
Rubin平台的核心理念被NVIDIA称为Extreme Co-Design(极限协同设计)。该设计强调GPU、CPU、网络、电源与散热系统在系统层面协同优化,以实现机架级AI计算架构。
本文涉及的供应商信息主要基于AI服务器产业链公开资料、行业结构及既有合作关系整理,用于帮助理解AI服务器产业链结构,列出的供应商仅作为行业参考。
第一章 NVL72整体结构
1.1 功能概述
NVL72是一个机架级AI计算系统,由多个计算模块组成的完整计算单元。在NVL72架构中,大量GPU被部署在同一机柜内部,并通过高速互连网络连接,从而形成统一计算系统。
可以把NVL72理解为:由72颗GPU组成的一台机架级计算节点。在实际部署中,一个NVL72机柜通常作为AI集群的基本计算单元,通过高速网络与其他机柜连接,构成更大规模的AI计算系统。
1.2 NVL72系统结构与核心组件
从硬件结构上看,NVL72机架内部主要由计算层与交换层两个核心部分组成。
计算层负责提供GPU算力,而交换层负责构建GPU之间的高速互连网络,使整柜GPU能够组成统一计算系统。
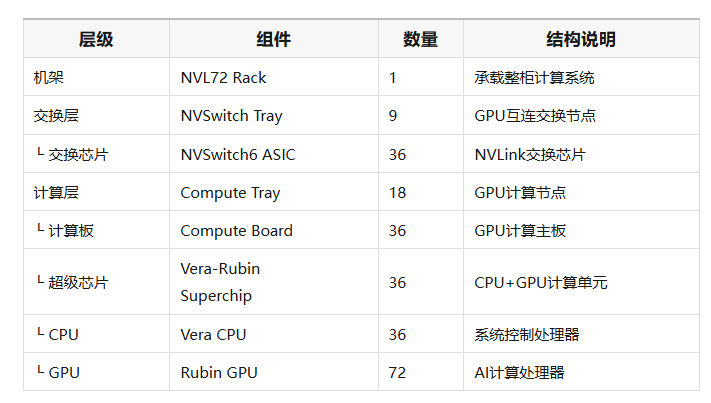
NVL72机架的主要硬件结构如下,在计算层,每个Compute Tray内部安装两块GPU计算主板。每块计算板上部署一个Vera-Rubin Superchip,用于提供AI计算能力。
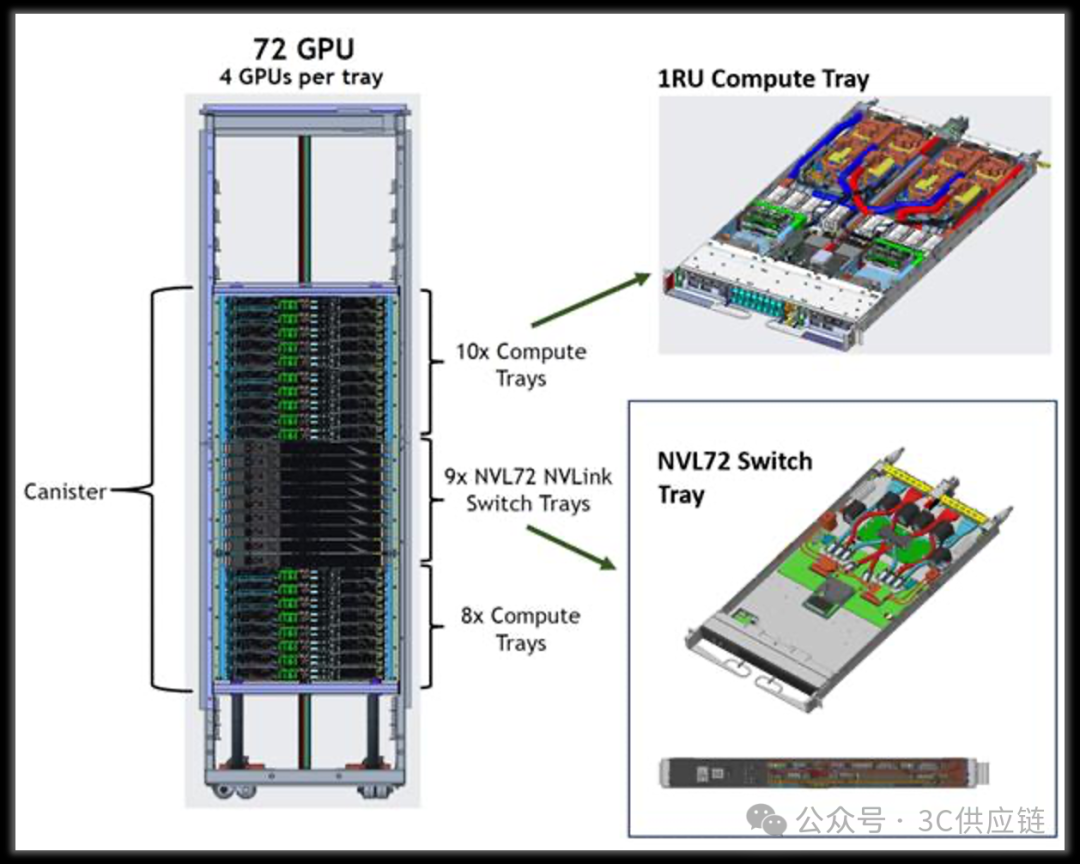
在交换层,机柜内部安装9个NVSwitch Tray。交换托盘内部集成NVSwitch ASIC交换芯片,用于构建GPU之间的高速互连网络,使整柜GPU能够组成统一计算系统。
1.3 NVL72系统模块划分
从硬件系统角度来看,一套NVL72机架可以进一步拆分为多个功能模块。这些模块共同构成完整的AI计算平台,包括计算节点、GPU互连网络、电源系统以及散热系统等。
为便于理解整套系统结构,本文将NVL72机架拆分为以下硬件系统:
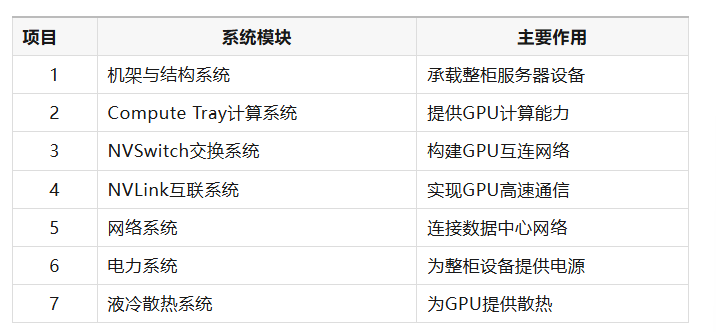
在接下来的章节中,将按照上述模块划分,逐一介绍NVL72系统中各个硬件模块的结构组成以及对应的关键物料与供应链。
第二章 机架与结构系统
2.1 功能概述
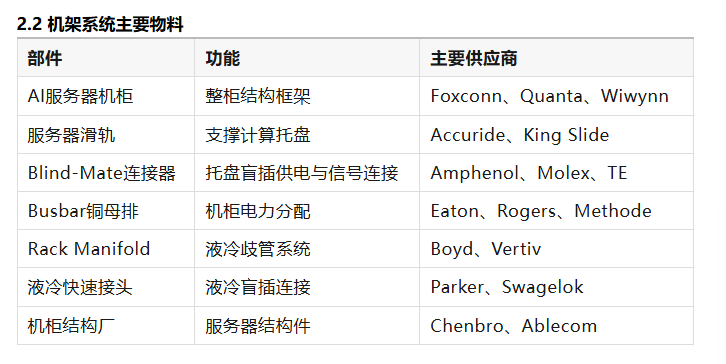
机架系统是NVL72的物理基础结构。
如果把NVL72看作一台大型计算机,那么机架相当于整套系统的基础框架,包括:机箱结构、电力分配框架、液冷散热基础设施。
Rubin平台在Compute Tray内部采用无内部线缆设计,通过板对板连接器实现模块化组装,所有服务器模块均采用托盘式结构,通过盲插连接器与机柜背板连接。
这种设计可以降低维护复杂度,同时提升系统可靠性,并提高数据中心部署效率。
第三章 Compute Tray计算系统
3.1 功能概述
Compute Tray是NVL72系统中的核心计算模块,负责提供AI模型训练与推理所需的GPU算力。
每个Compute Tray内部主要包含:GPU计算板、HBM高带宽内存、供电模块液冷散热系统
Rubin平台采用Vera-Rubin Superchip作为计算单元。每个Superchip包含:
1颗Vera CPU、2颗Rubin GPU
在NVL72机柜中,每个Compute Tray内部部署2个Superchip,因此每个Compute Tray包含2颗CPU和4颗GPU。
整柜NVL72系统配置为:36颗CPU、72颗GPU
其中CPU主要负责:任务调度、数据管理、GPU协同控制,GPU则负责执行AI模型训练与推理计算。
通过NVLink互连网络,这些GPU可以组成统一计算域,从而支持大规模并行计算。
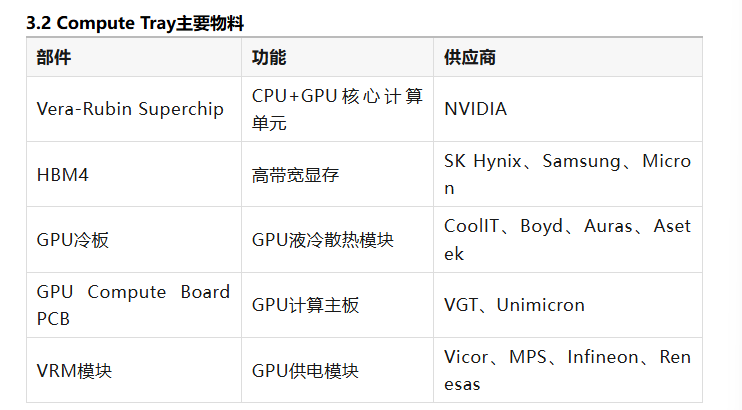
在Compute Tray中,GPU计算板是核心硬件,其上集成GPU、HBM内存以及供电模块,并通过NVLink接口与NVSwitch网络连接。
随着AI服务器功耗持续提升,GPU冷板散热能力与电源模块功率密度也成为Compute Tray设计中的关键因素。
3.3 GPU封装与HBM4供应链
Rubin GPU采用先进封装技术,将GPU芯片与HBM4高带宽内存集成在同一封装中,以实现更高的内存带宽和计算性能。
当前AI GPU普遍采用TSMC CoWoS先进封装技术,通过硅中介层(Interposer)实现GPU与HBM之间的高速连接。
GPU封装主要供应链包括:
封装厂:TSMC、ASE Technology、Amkor Technology
GPU封装基板(ABF Substrate)供应商:Ibiden、Shinko、Unimicron
HBM4供应商:SK Hynix、Samsung、Micron
随着AI服务器算力持续提升,GPU封装尺寸与复杂度也在不断增加。例如Rubin GPU封装基板面积已达到约8051mm²,并采用18层ABF substrate。
3.4 Rubin平台PCB结构
在AI服务器中,GPU计算板和交换网络板通常需要使用高层数高速PCB,以满足高速互连和高功率供电需求。
在Rubin NVL72系统中,服务器PCB主要包括Compute Board、NVSwitch Board以及机柜Midplane等不同类型。
根据产业链资料,Rubin平台PCB结构大致如下:
Compute Board 26层HDI(6+14+6)
NVSwitch Board 32层PTH
Midplane 44层PTH
随着AI服务器算力持续提升,服务器PCB层数与复杂度也不断增加。例如Rubin平台的Midplane PCB层数已达到44层,这对高速信号设计和PCB制造能力提出更高要求。
主要服务器PCB供应商包括:VGT、Unimicron、WUS、TTM、ISU
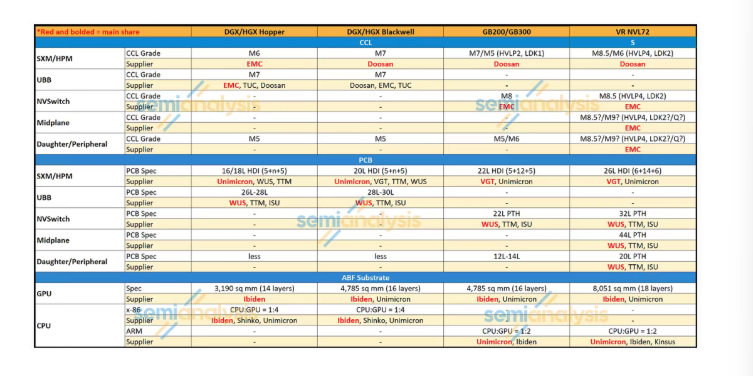
3.5 SOCAMM系统内存
Rubin CPU采用SOCAMM内存模块提供系统内存。
SOCAMM是一种面向数据中心CPU设计的高带宽内存模块,可在服务器主板上实现更高的内存容量和带宽。
SOCAMM供应链主要包括:Micron、Samsung、SK Hynix
通过SOCAMM模块,Vera CPU可以获得更大的系统内存容量,从而更好地支持AI训练中的数据调度与管理。
第四章 NVSwitch交换系统
4.1 功能概述
NVSwitch是NVL72系统中的GPU交换网络核心。
如果将GPU视为计算节点,那么NVSwitch可以理解为这些计算节点之间的高速交换网络,用于实现GPU之间的大规模通信。
NVSwitch系统主要负责:
构建GPU互连网络转发GPU之间的数据通信支持大规模并行计算任务
通过NVSwitch交换网络,NVL72机柜内部的72颗GPU可以组成统一的GPU计算域,并实现高速数据交换。
在系统结构上,NVL72机柜内部安装多个NVSwitch Tray,每个交换托盘内部集成多颗NVSwitch交换芯片,通过NVLink互连网络连接计算节点,从而构建完整的GPU互连架构。
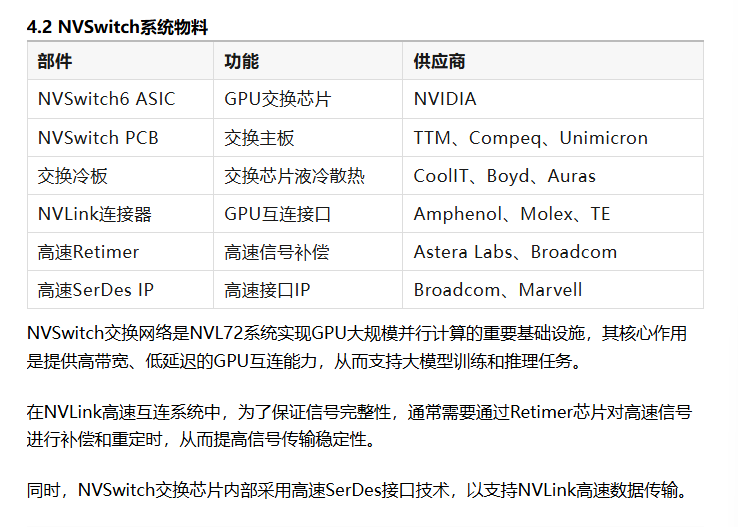
第五章 NVLink互联系统
5.1 功能概述
NVLink是NVL72系统内部GPU之间的数据通信网络。
可以将NVLink理解为AI服务器内部的高速数据互连系统,用于实现GPU之间的大规模数据交换。
与传统PCIe总线相比,NVLink提供更高的带宽和更低的通信延迟,因此更适合AI模型训练和推理等高性能计算任务。
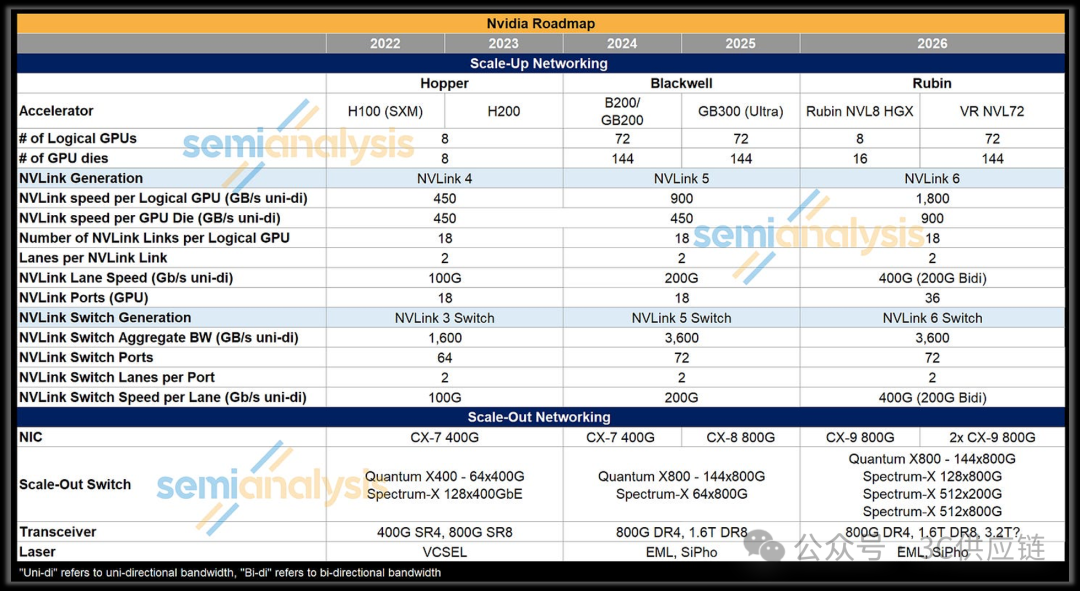
NVLink互联系统主要承担以下功能:
实现GPU之间的高速通信支持GPU显存共享提升分布式AI计算效率
在NVL72系统中,GPU计算节点通过NVLink连接到NVSwitch交换网络,从而构建整柜GPU互连架构。
5.2 NVLink系统物料
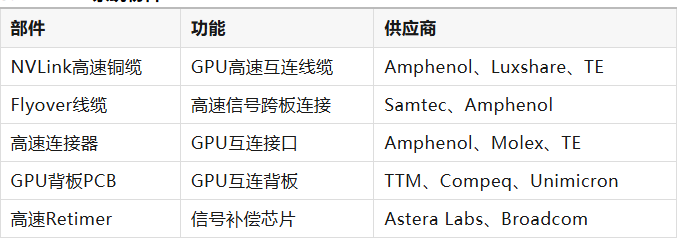
NVLink互联系统是NVL72机柜内部实现GPU大规模并行计算的重要基础设施,其核心目标是提供高带宽、低延迟的数据通信能力。
在高速互连系统中,为了降低信号损耗,部分NVLink信号通过Flyover线缆直接连接交换板和计算板,从而减少高速信号在PCB内部的传输距离。
同时,在长距离高速链路中,通常需要通过Retimer芯片对信号进行补偿和重定时,以保证高速数据传输的稳定性。
第六章 网络系统
6.1 功能概述
NVL72机柜通常不会单独运行,而是部署在大规模AI数据中心集群中。
多个NVL72机柜通过高速网络互联,可以构建大规模AI计算集群,例如NVIDIA提出的SuperPOD系统。
在这种架构中,单个NVL72机柜作为一个计算节点,通过数据中心网络与其他机柜连接,从而实现更大规模的AI模型训练与推理任务。
网络系统主要承担以下功能:
连接不同NVL72机柜支持分布式AI计算任务提供数据中心网络通信能力
在Rubin平台中,网络系统通常由高速网卡、DPU以及数据中心交换网络共同构成。
6.2 网络系统物料
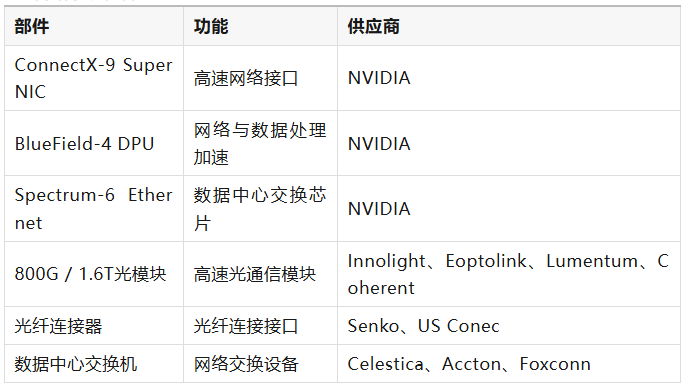
NVL72机柜通常通过高速光网络连接到数据中心交换网络。在AI数据中心中,多个NVL72机柜通过高速以太网或InfiniBand网络互联,从而构建大规模AI计算集群。
随着AI集群规模不断扩大,数据中心网络带宽需求也持续提升,因此新一代AI服务器通常采用800G甚至1.6T级别的高速光模块。
第七章 电力系统
7.1 功能概述
电力系统是NVL72机架运行的重要基础设施。
AI服务器的功耗远高于传统服务器,因此NVL72需要专门设计的高功率供电架构,以满足GPU计算节点的大规模电力需求。
在NVL72系统中,电力系统主要承担以下功能:
为GPU计算节点提供稳定电源为网络与交换系统提供电力支持整柜设备的高功率运行
Rubin NVL72通常采用48V高功率供电架构。相比传统12V服务器供电系统,48V供电可以降低电流损耗并提高供电效率,因此已成为新一代AI服务器的主流供电方案。
电力传输路径通常为:AC输入 → PSU → Busbar → DC-DC → GPU计算节点
通过这种分层供电架构,可以实现整柜设备的高功率稳定运行。
7.2 电力系统物料
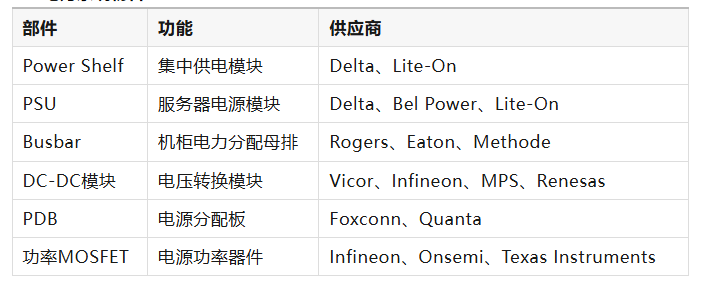
在AI服务器电源系统中,PSU模块通常负责将数据中心交流电转换为48V直流电,并通过Busbar母排系统将电力分配到各个计算节点。
在计算节点内部,DC-DC模块负责将48V电压进一步转换为GPU和CPU所需的低电压电源,从而满足高性能计算芯片的供电需求。
随着AI服务器功耗持续提升,高效率电源设计和高功率密度电源模块已成为AI服务器电力系统的重要发展方向。
第八章 液冷散热系统
8.1 功能概述
随着GPU功耗持续提升,传统风冷已经难以满足AI服务器的散热需求。因此,新一代AI服务器普遍采用液冷散热方案。
Rubin NVL72采用单相直接液冷系统(Direct Liquid Cooling),通过冷却液直接带走GPU等高功耗芯片产生的热量,从而实现更高效的散热能力。
在这种架构中,冷却液通过机柜内部的液冷管路流经GPU冷板,并将热量传输到数据中心冷却系统。
液冷系统主要承担以下功能:
为GPU计算节点提供散热降低服务器运行温度提高系统稳定性与能效
典型散热路径为:CDU → 机柜液冷管路 → GPU冷板 → 回水系统
Rubin NVL72通常支持约45°C热水液冷系统,这种高温液冷方案可以减少数据中心制冷能耗,从而提升整体能效。
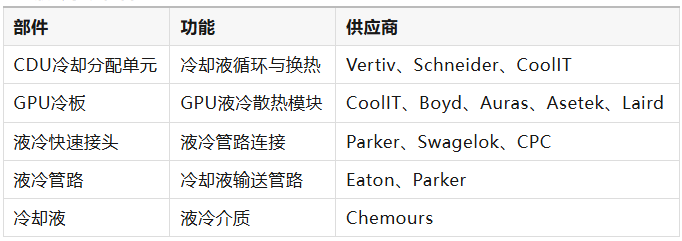
在液冷系统中,CDU通常负责控制冷却液循环,并将服务器产生的热量通过换热系统传输到数据中心冷却基础设施。
GPU冷板是液冷系统中的核心散热组件,其内部通常设计微通道结构,以提高散热效率。
为了方便服务器维护与热插拔,液冷系统通常采用快速接头(Quick Disconnect)连接液冷管路,从而实现设备快速维护和更换。
随着AI服务器复杂度持续提升,自动化装配正在成为新一代AI服务器制造的重要趋势。
在L10层级,目前具备Rubin Compute Tray自动化装配能力的厂商主要包括Foxconn、Quanta和Wistron。相比Blackwell平台曾存在较多Compute Tray组装厂商,Rubin平台的自动化制造能力正在向少数供应商集中。
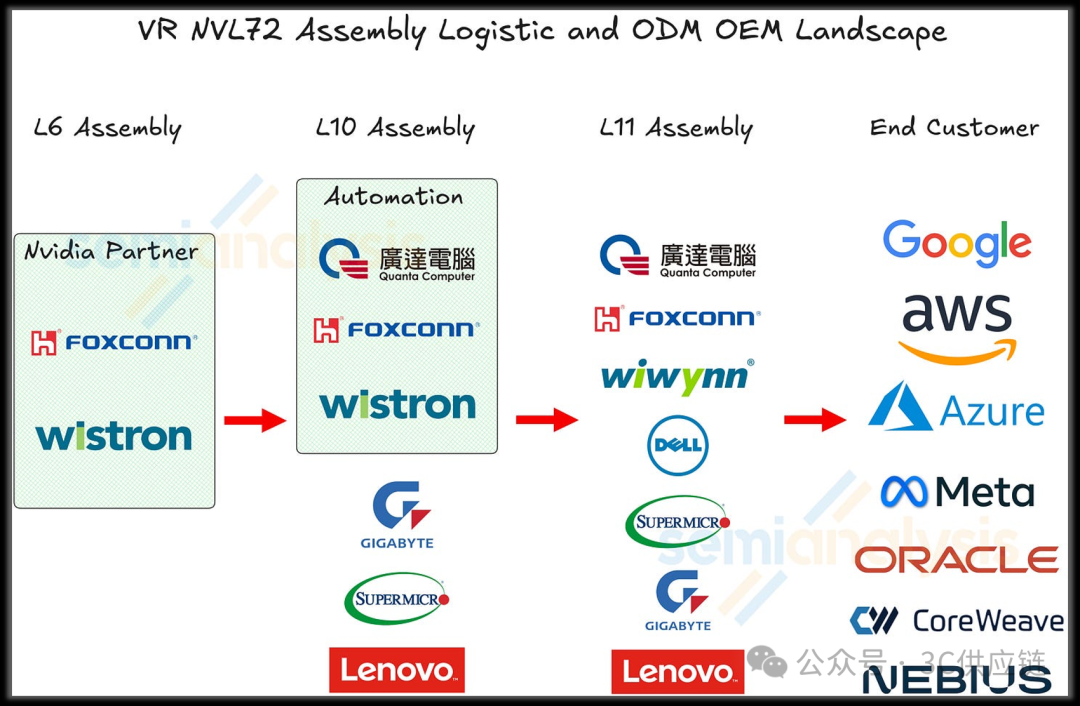
在更上游的L6层级(板级PCBA),Wistron与Foxconn仍然是Blackwell与Rubin平台的主要制造商。而在最终的L11阶段,各ODM厂商再将Compute Tray与NVSwitch等模块集成至NVL72机架,完成整柜AI服务器生产。
原文如上
欢迎大家关注原博主,3C供应链,大概看下来还是很专业的,毕竟产业链消息要比吹票产业链的消息靠谱的多。
也就算帮大家提前避坑了。也欢迎大家留言转发,谢谢大家。
$工业富联(SH601138)$ $中际旭创(SZ300308)$ $新易盛(SZ300502)$
只能圈3个公司,剩下的英文简称自己找吧,不会的就问AI,谢谢大家。
本话题在雪球有36条讨论,点击查看。
雪球是一个投资者的社交网络,聪明的投资者都在这里。
点击下载雪球手机客户端 http://xueqiu.com/xz]]>
#英伟达Vera #Rubin #NVL72服务器架构与供应链解析